

DevOps · GitLab · Automatización
GitLab CI/CD: cómo automatizamos despliegues y mejoramos la colaboración del equipo
GitLab CI/CD puede cambiar por completo la forma en la que un equipo entrega software. No solo porque permite automatizar despliegues, sino porque reduce errores, elimina cuellos de botella y obliga a trabajar con un proceso más ordenado, más visible y más seguro.
Durante mucho tiempo, en uno de nuestros proyectos dependíamos de una persona para desplegar. El código se desarrollaba en equipo, pero el paso final seguía siendo manual. Si esa persona no podía conectarse al servidor, el despliegue se quedaba bloqueado. Si alguien subía un cambio sin probar bien, el riesgo llegaba directamente al cliente.
Ese modelo puede funcionar durante un tiempo en equipos pequeños. Sin embargo, tarde o temprano aparece el problema: el despliegue deja de ser una tarea técnica y se convierte en un punto débil del proyecto.
En este artículo te cuento cómo pasamos de despliegues manuales a un flujo automatizado con GitLab CI/CD, qué aprendimos durante el proceso y qué estructura puedes usar si trabajas con proyectos Laravel, Vue.js, Tailwind CSS y Docker.
Idea clave: automatizar despliegues con GitLab CI/CD no consiste solo en ejecutar comandos desde una pipeline. Consiste en convertir un proceso manual, frágil y dependiente de personas concretas en un flujo repetible, trazable y compartido por todo el equipo.
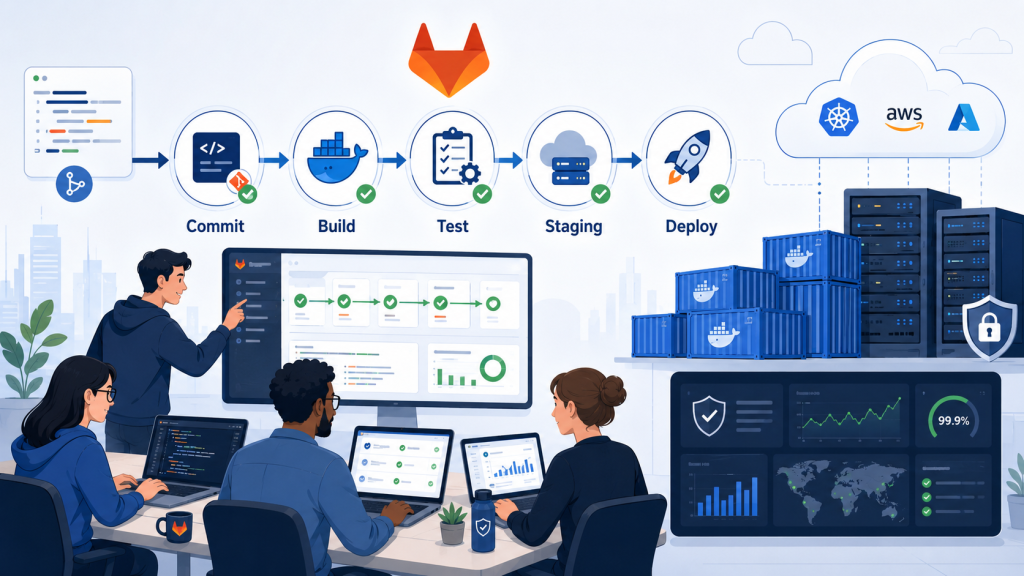
Resumen rápido
- GitLab CI/CD permite automatizar tareas como tests, construcción de assets, validaciones y despliegues.
- Los despliegues manuales generan dependencia, errores humanos y falta de trazabilidad.
- Un pipeline bien definido ayuda a separar entornos como preproducción, staging y producción.
- Las variables de entorno permiten gestionar credenciales sin escribir secretos en el código.
- Los jobs manuales son útiles para proteger despliegues críticos.
- La automatización no sustituye el criterio técnico, pero sí reduce tareas repetitivas y errores evitables.
Tabla de contenidos
- El problema: despliegues manuales y dependencia de una sola persona
- Qué es GitLab CI/CD y por qué ayuda
- Cómo implementamos GitLab CI/CD en el equipo
- Cómo funciona el fichero .gitlab-ci.yml
- Instalación de GitLab Runner en Ubuntu
- Ejemplo de pipeline para Laravel, Vue.js, Tailwind CSS y Docker
- Gestión segura de variables de entorno
- Reglas, jobs manuales y control de ejecución
- Errores habituales y aprendizajes prácticos
- Buenas prácticas para un pipeline más profesional
- Qué cambió en el equipo después de automatizar
- Conclusión
El problema: despliegues manuales y dependencia de una sola persona
Hace unos meses, en un proyecto desarrollado con Laravel, Vue.js, Tailwind CSS y una arquitectura basada en Docker, nos encontramos con un problema bastante común en equipos pequeños: el despliegue dependía demasiado de una sola persona.
El equipo podía desarrollar funcionalidades, revisar código y avanzar en el sprint. No obstante, cuando llegaba el momento de subir cambios al entorno del cliente, el proceso pasaba por mí. Yo era quien tenía acceso operativo al servidor y quien ejecutaba los pasos finales.
Al principio parecía una forma razonable de mantener el control. Sin embargo, el control manual tiene un coste: crea dependencia, reduce la autonomía del equipo y aumenta el riesgo de error.
Señal de alerta: si solo una persona sabe desplegar, el problema no es solo técnico. También es organizativo. El conocimiento crítico está concentrado y el equipo no puede cerrar el ciclo completo de entrega de forma autónoma.
Cuando el despliegue se convierte en un cuello de botella
El problema se hizo evidente un día en el que no pude conectarme al servidor del cliente. Habíamos cerrado un sprint con varias funcionalidades importantes y el equipo estaba listo para entregar. Sin embargo, el despliegue no podía avanzar porque dependía de mi acceso.
El cliente esperaba la actualización. El equipo no podía hacer mucho más. Y el proceso, que hasta ese momento parecía controlado, mostró su punto débil: no era repetible, no era compartido y no estaba suficientemente automatizado.
Ese fue el detonante para replantear el flujo de trabajo e introducir GitLab CI/CD como pieza central del proceso de entrega.
Los riesgos reales de desplegar a mano
Antes de automatizar, nuestros despliegues tenían varios problemas claros:
- Dependencia operativa. Si la persona con acceso no estaba disponible, el despliegue se bloqueaba.
- Errores humanos. Un comando mal ejecutado, una rama incorrecta o una migración olvidada podían generar incidencias.
- Falta de trazabilidad. No siempre quedaba claro qué se había desplegado, cuándo y con qué validaciones previas.
- Ausencia de validación automática. Si no había tests o checks previos, el riesgo viajaba directamente a producción.
- Menor autonomía del equipo. Otros desarrolladores podían terminar tareas, pero no cerrar el ciclo completo de entrega.
Además, vivimos una situación especialmente incómoda: una funcionalidad se desplegó sin haber sido suficientemente probada y una parte del producto dejó de funcionar durante unas horas. El cliente detectó el fallo antes que nosotros. A nivel técnico se podía corregir, pero a nivel reputacional fue una señal de alerta.
Por tanto, necesitábamos algo más que “hacer despliegues más rápidos”. Necesitábamos un proceso más fiable.

Qué es GitLab CI/CD y por qué ayuda a los equipos de desarrollo
GitLab CI/CD es el sistema de integración continua y entrega o despliegue continuo integrado en GitLab. Permite definir pipelines que se ejecutan automáticamente cuando ocurre un evento en el repositorio: un push, un merge request, una etiqueta, una rama concreta o una ejecución manual.
En la práctica, un pipeline puede encargarse de tareas como:
- instalar dependencias;
- ejecutar tests;
- analizar calidad de código;
- compilar assets frontend;
- construir imágenes Docker;
- ejecutar migraciones;
- desplegar en preproducción, staging o producción;
- notificar errores al equipo.
La idea principal es sencilla: cada cambio importante debería pasar por un proceso controlado antes de llegar a un entorno real.
Definición práctica: un pipeline de CI/CD es una receta ejecutable. Define qué pasos debe seguir el proyecto para validar, construir y desplegar software de forma consistente.
Integración continua: validar antes de integrar
La integración continua, o CI, consiste en validar los cambios de código de forma frecuente. Cada vez que un desarrollador sube cambios, GitLab puede ejecutar una serie de jobs para comprobar que el proyecto sigue funcionando.
Por ejemplo, un pipeline de integración continua puede ejecutar tests de Laravel, revisar estilo de código PHP, comprobar dependencias de Node.js o compilar los assets generados con Tailwind CSS y Vue.js.
De esta forma, el equipo detecta errores antes de fusionar el código en ramas principales.
Entrega continua y despliegue continuo: no son exactamente lo mismo
Conviene aclarar un matiz importante. Muchas veces se habla de CI/CD como si el CD significara siempre “despliegue continuo”. Sin embargo, también puede referirse a “entrega continua”.
- Entrega continua: el sistema deja el software listo para desplegar, pero el paso final puede requerir aprobación manual.
- Despliegue continuo: el sistema despliega automáticamente cuando se cumplen las condiciones definidas.
En proyectos con clientes, datos sensibles o entornos críticos, suele ser recomendable empezar con entrega continua. Es decir, automatizar validaciones, preparar el despliegue y dejar producción protegida mediante aprobación manual.
Así ganas velocidad sin perder control.
Importante: no todos los proyectos necesitan despliegue automático a producción. En muchos casos, lo más sensato es automatizar validaciones y dejar el despliegue final como una acción manual, auditada y aprobada.
Cómo implementamos GitLab CI/CD en nuestro flujo de trabajo
En nuestra empresa ya utilizábamos GitLab como repositorio central. Por tanto, la decisión natural fue aprovechar GitLab CI/CD en lugar de introducir una herramienta externa.
El objetivo inicial no era crear el pipeline perfecto. El objetivo era resolver tres problemas concretos:
- evitar que el despliegue dependiera de una sola persona;
- reducir errores antes de llegar al entorno del cliente;
- dar más autonomía al equipo sin perder control sobre producción.
A partir de ahí, definimos una estrategia por entornos.
Separación de entornos: pre, staging y producción
El primer paso fue separar el flujo según el entorno de destino.
- Preproducción: entorno para pruebas internas rápidas.
- Staging: entorno más estable para validación funcional o revisión del cliente.
- Producción: entorno final, protegido y con ejecución controlada.
Esta separación nos permitió trabajar con más seguridad. Un cambio podía probarse primero en preproducción, después validarse en staging y, finalmente, pasar a producción con aprobación explícita.
Además, cada entorno podía tener sus propias variables, URLs, credenciales y reglas de ejecución.
Decisión de arquitectura: separar entornos no es burocracia. Es una forma de reducir riesgo. Cada entorno debe tener un propósito, unas credenciales y unas reglas de despliegue diferentes.
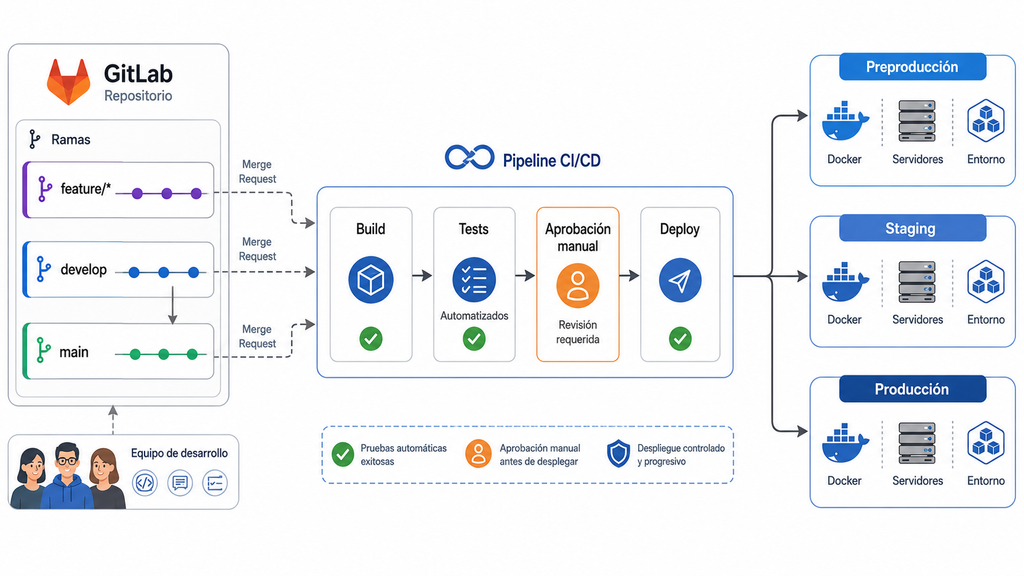
Más autonomía para el equipo
Con el nuevo flujo, cualquier miembro autorizado del equipo podía lanzar determinados pipelines sin depender de una conexión manual al servidor. Por ejemplo, un desarrollador podía desplegar una rama en staging para probar una funcionalidad concreta.
Sin embargo, producción seguía protegida. No queríamos que la automatización se convirtiera en una barra libre de despliegues. Por eso, configuramos reglas y jobs manuales para que los cambios críticos necesitaran revisión previa.
El resultado fue un equilibrio razonable: más velocidad en entornos de prueba y más control en producción.
Validaciones antes de desplegar
El siguiente paso fue añadir validaciones automáticas. En nuestro caso, el pipeline debía comprobar al menos tres cosas:
- que los tests de backend pasaban correctamente;
- que los assets frontend podían compilarse sin errores;
- que los comandos de despliegue se ejecutaban en el entorno adecuado.
Más adelante, este flujo se puede ampliar con análisis estático, revisión de vulnerabilidades, control de dependencias, pruebas end-to-end o validación de configuración Docker.
Si trabajas con Moodle, Laravel o aplicaciones EdTech, este enfoque conecta muy bien con otros procesos de automatización. Por ejemplo, puedes complementarlo con tareas programadas, validaciones de plugins o despliegues controlados de integraciones. En esta línea, también puede interesarte revisar el artículo sobre automatización en Moodle con tareas programadas.
Cómo funciona el fichero .gitlab-ci.yml
El corazón de GitLab CI/CD es el fichero .gitlab-ci.yml. Este archivo se coloca en la raíz del repositorio y define qué debe hacer GitLab cuando se ejecuta un pipeline.
Normalmente, el fichero contiene tres conceptos básicos:
- Stages: las fases del pipeline, como build, test o deploy.
- Jobs: las tareas concretas que se ejecutan dentro de cada fase.
- Rules: las condiciones que deciden cuándo se ejecuta cada job.
Un ejemplo básico podría ser este:
stages:
- build
- test
- deploy
build_job:
stage: build
script:
- echo "Compilando el código..."
- npm install
- npm run build
test_job:
stage: test
script:
- echo "Ejecutando pruebas..."
- npm test
deploy_staging:
stage: deploy
script:
- echo "Desplegando en staging..."
- npm run deploy:staging
only:
- mainEste pipeline tiene tres fases: construir, probar y desplegar. Además, el despliegue a staging queda limitado a la rama principal, aunque en proyectos reales puede ser más recomendable usar rules y jobs manuales.
Consejo práctico: empieza con un pipeline pequeño. Primero tests y build. Después staging. Finalmente producción con aprobación manual. Intentar automatizar todo desde el primer día suele generar más fricción que valor.
Componentes clave de GitLab CI/CD
Antes de entrar en el ejemplo completo, conviene entender las piezas principales:
- Pipeline: ejecución completa del flujo definido en
.gitlab-ci.yml. - Job: tarea individual dentro del pipeline.
- Stage: agrupación lógica de jobs.
- Runner: agente que ejecuta los jobs.
- Artifact: fichero o carpeta generada por un job y reutilizable después.
- Environment: entorno de destino, como staging o producción.
- Variable: dato configurable que puede usarse sin escribirlo directamente en el código.
La documentación oficial de GitLab CI/CD explica estos conceptos con mucho detalle. Aun así, mi recomendación es empezar con un pipeline pequeño y ampliarlo poco a poco.
Instalación de GitLab Runner en Ubuntu
Para ejecutar pipelines necesitas un GitLab Runner. El runner es el agente encargado de ejecutar los jobs definidos en el fichero .gitlab-ci.yml.
Puede ejecutarse en diferentes modos. Los más habituales son:
- Shell executor: ejecuta comandos directamente en el servidor.
- Docker executor: ejecuta jobs dentro de contenedores.
- Kubernetes executor: ejecuta jobs en un clúster Kubernetes.
Para un primer caso sencillo, especialmente si quieres desplegar en un servidor ya existente, el ejecutor tipo shell puede ser suficiente. No obstante, en entornos más maduros suele ser preferible construir artefactos o imágenes Docker y desplegarlas de forma más controlada.
Punto de seguridad: un runner instalado en un servidor con acceso a producción debe tratarse como una pieza crítica de infraestructura. Protege las ramas, limita quién puede ejecutar pipelines y evita runners compartidos para despliegues sensibles.
Actualizar el servidor
Antes de instalar el runner, conviene actualizar el sistema operativo:
sudo apt update && sudo apt upgrade -yInstalar GitLab Runner
Después, puedes instalar GitLab Runner siguiendo la documentación oficial de GitLab Runner para Linux. Un flujo habitual en Ubuntu consiste en añadir el repositorio oficial e instalar el paquete:
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh | sudo bash
sudo apt install gitlab-runnerEn servidores de producción, revisa siempre el contenido de scripts externos antes de ejecutarlos y utiliza documentación oficial. Esta precaución es especialmente importante cuando trabajas con infraestructura de clientes.
Registrar el runner
Una vez instalado, el runner debe registrarse en GitLab. El comando habitual es:
sudo gitlab-runner registerDurante el registro, GitLab solicitará varios datos:
- URL de la instancia de GitLab.
- Token de registro del runner.
- Descripción del runner.
- Etiquetas asociadas, como
ubuntu,dockerostaging. - Tipo de executor, como
shellodocker.
Las etiquetas son importantes porque permiten decidir qué jobs puede ejecutar cada runner. Por ejemplo, puedes tener un runner para staging y otro diferente para producción.
Después del registro, puedes iniciar el servicio:
sudo gitlab-runner startComprobar el estado del runner
Después del registro, puedes comprobar su estado con:
sudo gitlab-runner statusSi el servicio está activo, GitLab ya podrá enviarle jobs cuando se cumplan las reglas definidas en el pipeline.
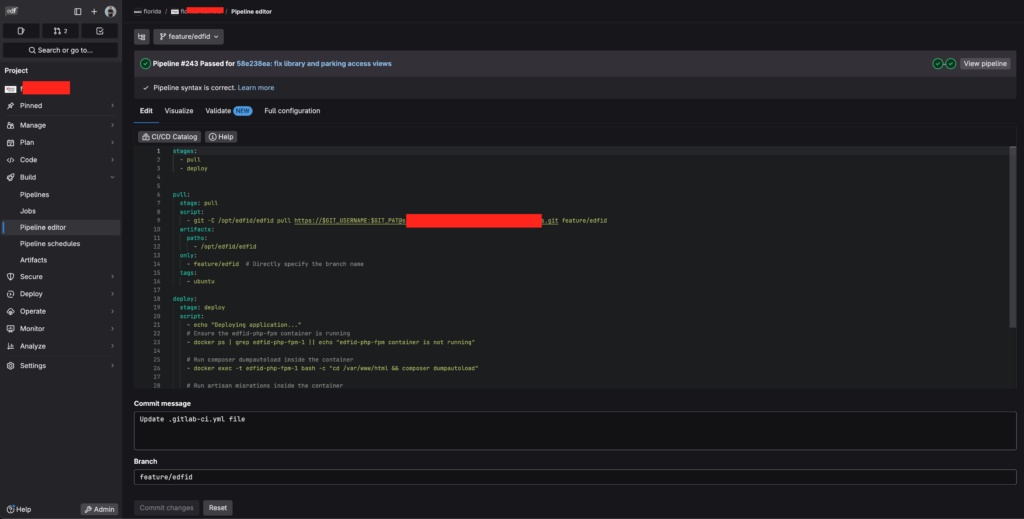
Ejemplo de pipeline para Laravel, Vue.js, Tailwind CSS y Docker
En nuestro caso, el proyecto combinaba Laravel en backend, Vue.js y Tailwind CSS en frontend, y una arquitectura Docker con contenedores para PHP-FPM, Apache y MySQL.
El pipeline debía cubrir tres necesidades:
- actualizar el código del proyecto;
- ejecutar pruebas de Laravel;
- desplegar la aplicación ejecutando comandos dentro del entorno Docker.
A continuación tienes un ejemplo adaptado y anonimizado. Los nombres de proyecto, dominio y contenedores son genéricos.
Nota práctica: este ejemplo está pensado para un flujo sencillo con runner instalado en el servidor de despliegue. En proyectos más avanzados, suele ser preferible construir una imagen Docker versionada, publicarla en un registry y desplegar esa imagen en el entorno correspondiente.
stages:
- pull_code
- test
- deploy_app
pull_code:
stage: pull_code
script:
- git -C /opt/myapp pull https://$GIT_USERNAME:$GIT_PAT@source.example.com/myorg/myapp.git main
artifacts:
paths:
- /opt/myapp
only:
- main # Solo se ejecuta en la rama 'main'
tags:
- ubuntu # Se ejecuta en un runner con la etiqueta 'ubuntu'
test:
stage: test
script:
- echo "Ejecutando pruebas de Laravel..."
# Ejecuta pruebas unitarias de Laravel
- docker exec -t php-container bash -c "cd /var/www/html && php artisan test"
only:
- main
tags:
- ubuntu
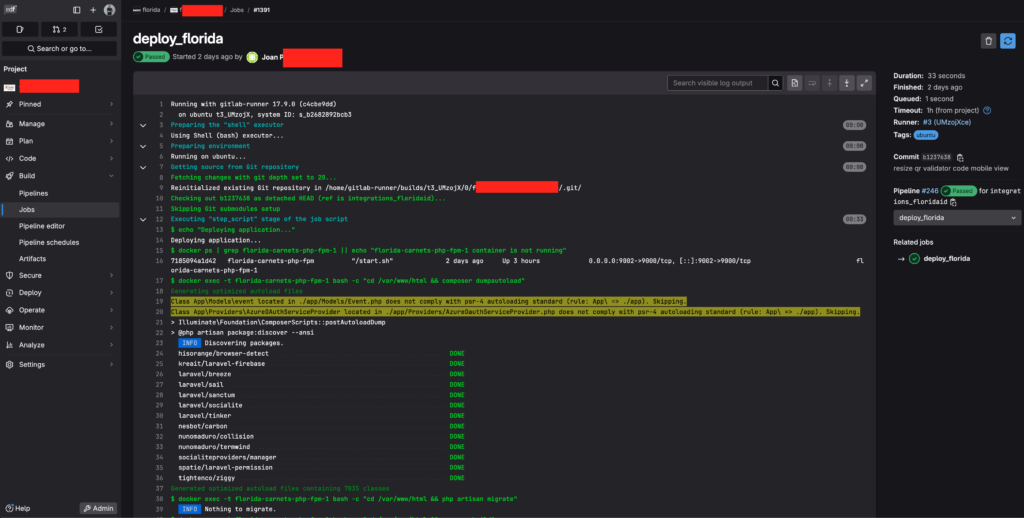
deploy_app:
stage: deploy_app
script:
- echo "Desplegando aplicación..."
# Verifica si el contenedor de PHP está en ejecución
- docker ps | grep php-container || echo "El contenedor de PHP no está en ejecución"
# Ejecuta composer dumpautoload dentro del contenedor
- docker exec -t php-container bash -c "cd /var/www/html && composer dumpautoload"
# Ejecuta migraciones de Laravel dentro del contenedor
- docker exec -t php-container bash -c "cd /var/www/html && php artisan migrate"
# Compila el frontend, ejecuta NPM dentro del contenedor
- docker exec -t php-container bash -c "cd /var/www/html && npm run build"
only:
- main # Solo se ejecuta en la rama 'main'
tags:
- ubuntu # Se ejecuta en un runner con la etiqueta 'ubuntu'Cuidado con este punto: ejecutar builds o migraciones directamente sobre producción puede ser suficiente para una primera versión, pero no siempre es lo más robusto. En proyectos críticos, conviene construir artefactos versionados, probarlos y desplegar exactamente esa versión.
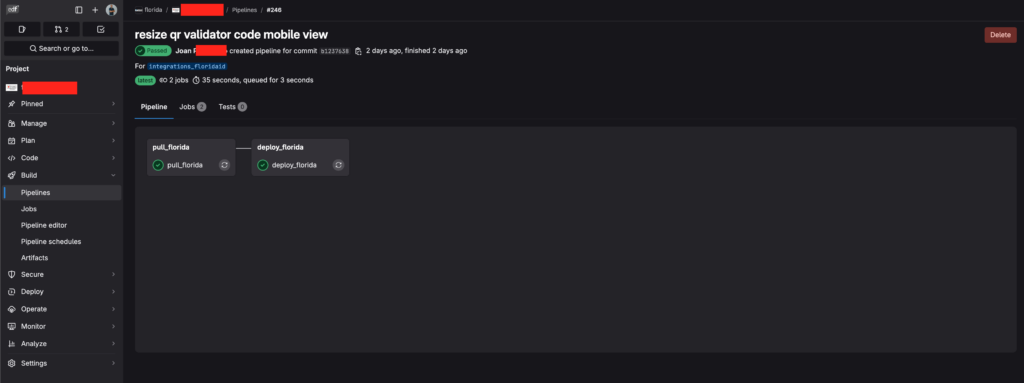
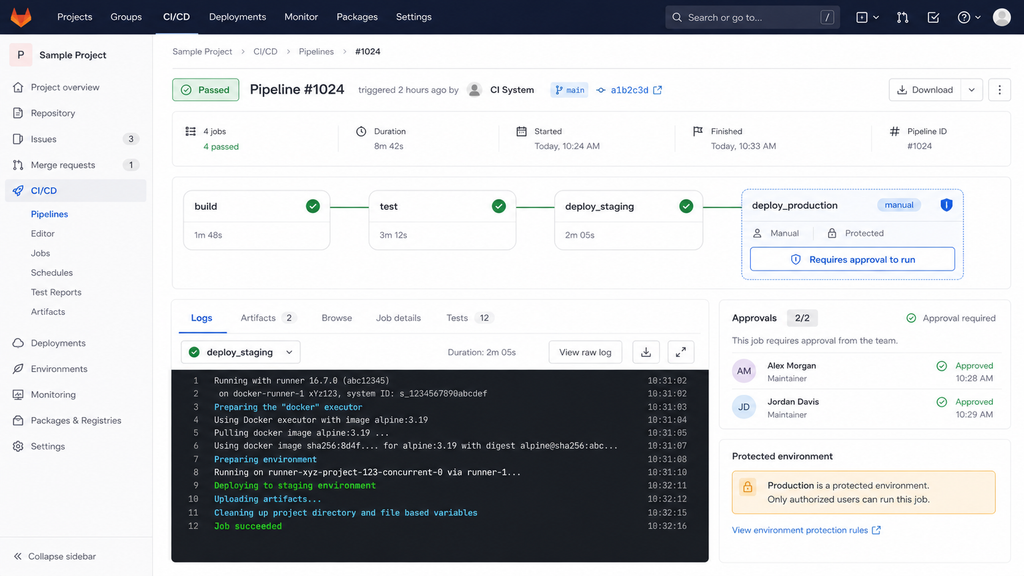
Qué hace cada etapa del pipeline
El pipeline se divide en tres etapas claras.
1. pull_code
Actualiza el código del servidor a partir de la rama principal. En este ejemplo, el servidor ejecuta un git pull sobre una ruta concreta. Es un enfoque sencillo para empezar, pero conviene revisarlo si el proyecto crece.
2. test
Ejecuta los tests de Laravel dentro del contenedor PHP. Si los tests fallan, el pipeline se detiene y el despliegue no continúa.
3. deploy_app
Ejecuta las tareas necesarias para dejar la aplicación lista: actualización de autoload, migraciones y compilación frontend.
Visto de forma gráfica, un pipeline sencillo de GitLab CI/CD puede entenderse como una secuencia de validación y despliegue:

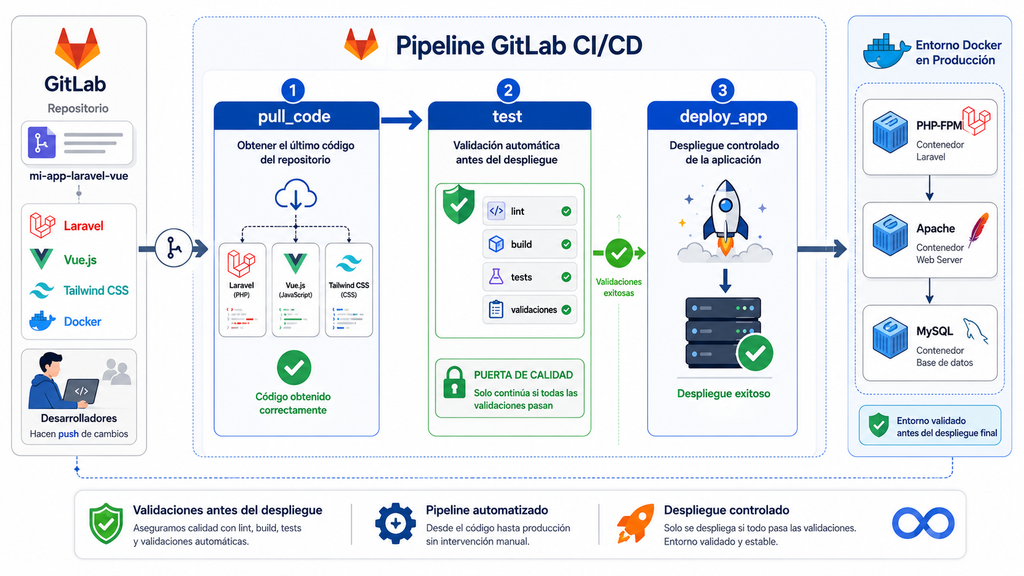
Una mejora recomendable: construir antes de desplegar
El ejemplo anterior funciona bien para un primer paso. Sin embargo, en equipos más maduros conviene evolucionar hacia un enfoque más robusto:
- construir una imagen Docker en el pipeline;
- publicarla en un registry;
- desplegar una versión concreta de esa imagen;
- evitar builds directamente en producción;
- poder hacer rollback a una versión anterior.
Este modelo mejora la trazabilidad. En lugar de desplegar “lo último de main”, despliegas una versión concreta, identificable y reproducible.
Este enfoque encaja especialmente bien cuando trabajas con productos EdTech, integraciones LTI, plugins Moodle o aplicaciones críticas. Si te interesa esta línea, también puedes revisar el artículo sobre plugin Moodle, API REST o LTI 1.3, porque plantea decisiones similares sobre arquitectura, despliegue y mantenimiento.
Gestión segura de variables de entorno en GitLab CI/CD
Las variables de entorno son una parte fundamental de GitLab CI/CD. Permiten configurar credenciales, tokens, rutas, URLs, nombres de entorno o parámetros de despliegue sin escribirlos directamente en el repositorio.
Esto es especialmente importante cuando necesitas acceder a repositorios privados, servidores externos, APIs o entornos con credenciales diferentes.
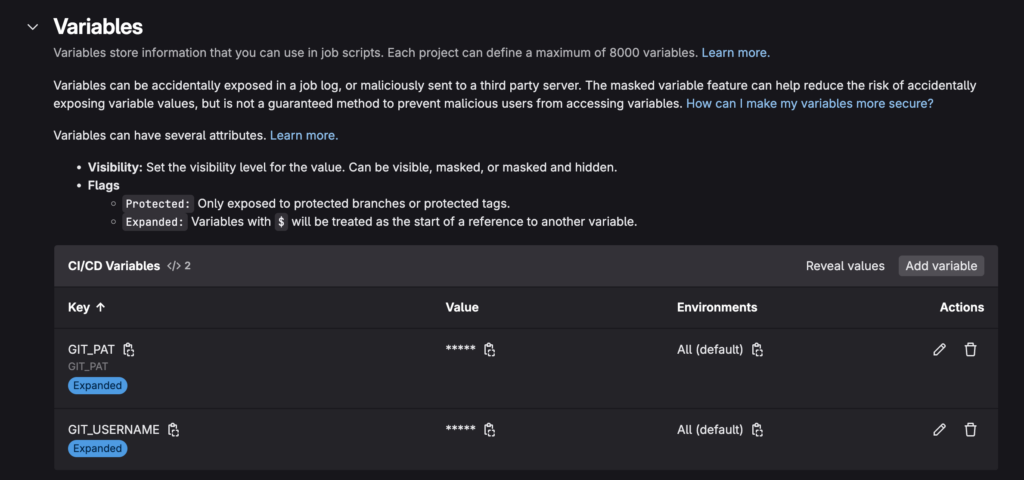
Variables a nivel de proyecto
Las variables a nivel de proyecto solo están disponibles dentro de ese repositorio. Son útiles para configuraciones específicas, como una URL de despliegue o una credencial concreta.
Algunos ejemplos habituales son:
DEPLOY_HOSTDEPLOY_USERSSH_PRIVATE_KEYAPP_ENVDOCKER_REGISTRY_PASSWORDGIT_USERNAMEGIT_PAT
Para configurarlas, entra en el proyecto de GitLab y ve a Settings > CI/CD > Variables.
Uso de variables de entorno en el pipeline
Una vez definidas, puedes usar las variables de entorno dentro del fichero .gitlab-ci.yml. En el caso de un repositorio privado, podrías ver algo parecido a esto:
pull_code:
stage: pull_code
script:
- git -C /opt/myapp pull https://$GIT_USERNAME:$GIT_PAT@source.example.com/myorg/myapp.git main
artifacts:
paths:
- /opt/myapp
only:
- main # Solo se ejecuta en la rama 'main'
tags:
- ubuntu # Se ejecuta en un runner con la etiqueta 'ubuntu'
Variables protegidas y enmascaradas
GitLab permite marcar variables como protegidas y enmascaradas.
- Protected: la variable solo está disponible en ramas o tags protegidos.
- Masked: el valor no se muestra en los logs del pipeline.
Para tokens, contraseñas o claves privadas, deberías usar variables enmascaradas. Además, si una credencial solo debe existir en producción, conviene limitarla a ramas protegidas.
La documentación oficial sobre variables de GitLab CI/CD es una referencia útil para configurar este punto con seguridad.
Regla de seguridad: si una credencial permite desplegar, acceder a un servidor o publicar imágenes Docker, debe tratarse como un secreto crítico. No debe aparecer en el repositorio, en capturas públicas ni en logs visibles.
Evita escribir tokens en comandos visibles
En algunos proyectos se usa un Personal Access Token para hacer pull del repositorio desde el servidor. Aunque puede funcionar, no siempre es la mejor opción. Si escribes el token dentro de una URL de Git, existe riesgo de exposición en logs, historial de comandos o procesos del sistema.
Siempre que sea posible, es mejor usar:
- deploy keys SSH;
- tokens con permisos mínimos;
- variables protegidas;
- runners específicos por entorno;
- rotación periódica de credenciales.
Si no tienes alternativa y debes usar un token, asegúrate de que esté enmascarado, protegido y limitado al alcance mínimo necesario.
Reglas, jobs manuales y control de ejecución en GitLab CI/CD
Una de las grandes ventajas de GitLab CI/CD es que permite decidir cuándo se ejecuta cada job. Esto evita que todos los pasos del pipeline se ejecuten siempre y permite proteger acciones sensibles.
Por ejemplo, puedes hacer que los tests se ejecuten en cada merge request, que staging se despliegue desde una rama concreta y que producción requiera aprobación manual.
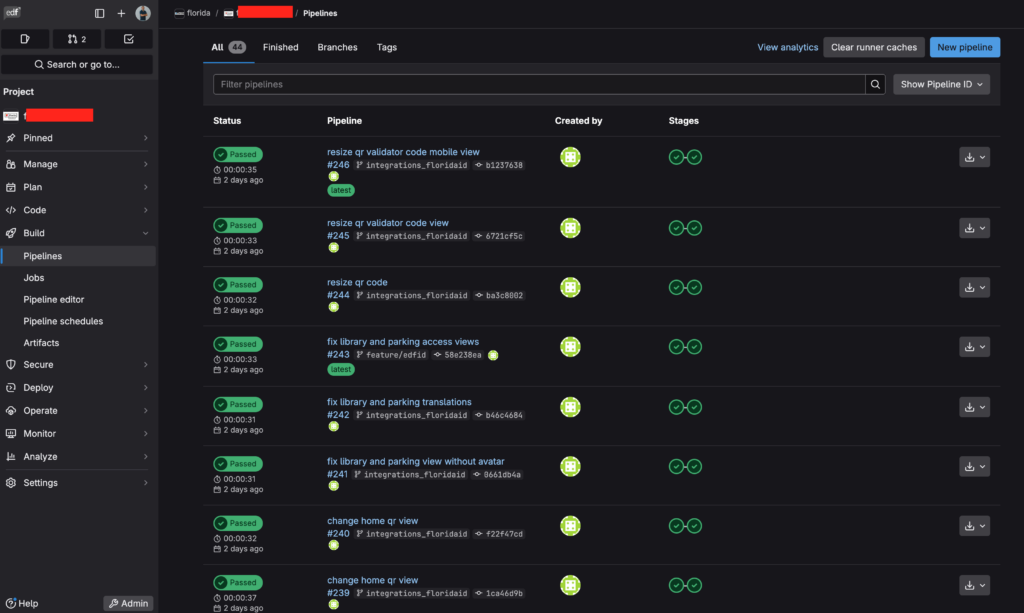
Activación de pipelines
Las pipelines pueden ejecutarse en diferentes situaciones:
- Push a una rama: cuando haces cambios y los subes al repositorio.
- Merge Request: cuando se crea o actualiza una propuesta de integración.
- Trigger manual: cuando alguien lanza una pipeline desde la interfaz.
- Schedules: cuando se programa una ejecución recurrente, por ejemplo cada noche.
Usar rules en lugar de depender solo de only y except
GitLab permite usar directivas como only, except y rules. Para pipelines nuevos, prefiero usar rules, porque permite expresar condiciones de forma más clara y flexible.
Un job limitado a la rama principal con only podría definirse así:
deploy_production:
stage: deploy
script:
- echo "Desplegando en producción..."
only:
- mainTambién puedes excluir una rama concreta con except:
test:
stage: test
script:
- echo "Ejecutando pruebas..."
except:
- developmentSin embargo, para pipelines actuales suele ser más expresivo usar rules. Por ejemplo:
deploy_staging:
stage: deploy
script:
- echo "Desplegando en staging..."
rules:
- if: '$CI_COMMIT_BRANCH == "staging"'
when: always
- if: '$CI_COMMIT_BRANCH == "main"'
when: manualPatrón recomendado: valida automáticamente todo lo que puedas, pero protege manualmente lo que pueda afectar al usuario final, a datos reales o a la disponibilidad del servicio.
Notificar fallos del pipeline
Otra opción útil es ejecutar un job cuando algo falla. Por ejemplo:
notify_failure:
stage: notify
script:
- echo "Algo salió mal. Notificando al equipo..."
when: on_failureEn un caso real, este job podría enviar una notificación a Slack, Discord, Microsoft Teams o cualquier sistema interno de seguimiento.
Errores habituales al empezar con GitLab CI/CD
Implementar GitLab CI/CD no consiste solo en escribir un YAML y esperar que todo funcione. Hay algunos errores frecuentes que conviene evitar desde el principio.
1. Automatizar un mal proceso
Si tu despliegue manual es caótico, automatizarlo sin revisarlo solo hará que el caos ocurra más rápido. Antes de escribir el pipeline, conviene documentar el proceso actual y detectar qué pasos sobran, cuáles faltan y qué riesgos existen.
2. Desplegar a producción sin aprobación
En productos críticos, producción debería estar protegida. Aunque el pipeline sea automático, no siempre interesa que cualquier cambio en main llegue directamente al usuario final.
Por eso, los jobs manuales son una buena primera medida de seguridad.
3. Guardar secretos en el repositorio
Nunca deberías guardar contraseñas, tokens, claves privadas o URLs sensibles directamente en el fichero .gitlab-ci.yml. Usa variables de entorno y aplica permisos mínimos.
4. No separar entornos
Preproducción, staging y producción no deberían compartir las mismas credenciales ni las mismas reglas de ejecución. Cada entorno tiene un propósito y un nivel de riesgo diferente.
5. Ejecutar migraciones sin estrategia
Las migraciones son uno de los puntos más delicados del despliegue. Antes de automatizarlas en producción, conviene revisar compatibilidad hacia atrás, copias de seguridad, ventanas de mantenimiento y posibilidad de rollback.
En Laravel, php artisan migrate --force es necesario en entornos no interactivos, pero no sustituye una buena estrategia de despliegue.
6. No revisar permisos del runner
Un runner con demasiados permisos puede convertirse en un riesgo. Si el runner puede ejecutar cualquier comando en un servidor de producción, debes proteger muy bien quién puede lanzar pipelines y desde qué ramas.
La automatización debe aumentar la seguridad del proceso, no abrir nuevas puertas innecesarias.
Resumen de errores a evitar: no automatices sin entender el proceso, no publiques secretos, no des permisos excesivos al runner, no despliegues producción sin control y no ejecutes migraciones críticas sin estrategia de rollback.
Buenas prácticas para un pipeline más profesional
Después de pasar por este proceso, estas son algunas buenas prácticas que aplicaría desde el principio en casi cualquier proyecto.
- Empieza pequeño. No intentes crear el pipeline perfecto el primer día.
- Separa validación y despliegue. Primero comprueba que el código funciona; después despliega.
- Protege producción. Usa ramas protegidas, variables protegidas y jobs manuales.
- No guardes secretos en el YAML. Usa variables de entorno.
- Etiqueta runners por entorno. Evita que cualquier runner pueda desplegar en cualquier sitio.
- Haz que los fallos sean visibles. Un pipeline que falla en silencio no sirve de mucho.
- Documenta el flujo. El equipo debe saber qué pasa cuando se hace push, merge o deploy.
- Revisa los logs. Los logs del pipeline son una fuente muy útil para detectar problemas de permisos, rutas o dependencias.
- Planifica rollback. Automatizar despliegues no elimina la necesidad de volver atrás si algo falla.
Además, conviene revisar periódicamente el pipeline. Igual que el código de la aplicación, el pipeline también acumula deuda técnica.

Qué cambió en el equipo después de automatizar
La adopción de GitLab CI/CD no solo mejoró los despliegues. También cambió la forma en la que trabajábamos como equipo.
Los cambios más importantes fueron estos:
- Menos dependencia individual. El proceso dejó de depender de una sola persona.
- Más autonomía. Los desarrolladores podían validar cambios en entornos controlados.
- Más confianza. Cada despliegue pasaba por un flujo común y visible.
- Menos errores repetitivos. Las tareas manuales se redujeron.
- Mejor trazabilidad. Quedaba registro de qué pipeline se ejecutó, cuándo y con qué resultado.
- Mejor conversación técnica. El equipo empezó a hablar más de procesos, pruebas, ramas, entornos y calidad.
Este último punto es importante. CI/CD no es solo una herramienta técnica. También es una forma de ordenar la colaboración.
Cuando el proceso está definido, el equipo discute menos sobre “quién despliega” y más sobre “qué condiciones debe cumplir un cambio para llegar a producción”. Esa conversación es mucho más sana.
Reflexión de equipo: CI/CD no solo mejora la entrega de software. También cambia la conversación interna: de “quién puede desplegar” a “qué garantías debe cumplir un cambio antes de llegar al usuario”.
Conclusión: GitLab CI/CD no es solo automatización, es una forma de trabajar mejor
Implementar GitLab CI/CD nos ayudó a resolver un problema muy concreto: los despliegues manuales se habían convertido en un cuello de botella. Sin embargo, el beneficio fue más allá de la automatización.
Al definir pipelines, separar entornos, añadir validaciones y proteger producción, el equipo empezó a trabajar con más autonomía y más seguridad. Ya no dependíamos de una persona concreta para cerrar el ciclo de entrega. Además, cada cambio importante pasaba por un proceso más visible y controlado.
La automatización no elimina la necesidad de criterio técnico. De hecho, la aumenta. Hay que decidir qué se valida, cuándo se despliega, qué credenciales se usan, qué ramas se protegen y qué ocurre si algo falla.
Por eso, CI/CD no debería verse solo como una herramienta para ir más rápido. Su verdadero valor está en crear un flujo de trabajo repetible, seguro y compartido.
Automatizar despliegues no significa perder control. Significa dejar de depender de la memoria, la disponibilidad y los comandos manuales de una sola persona.
Si tu equipo todavía despliega a mano, quizá no necesitas empezar con una arquitectura compleja. Puedes empezar con algo mucho más simple: un pipeline que ejecute tests, compile assets y deje el despliegue de producción como una acción manual.
Ese primer paso ya cambia la conversación. Y, muchas veces, también cambia la forma en la que el equipo entiende la calidad del software.
Pregunta para cerrar: si mañana tuvieras que desplegar sin la persona que normalmente lo hace, ¿tu equipo podría hacerlo con seguridad? Si la respuesta es no, quizá ha llegado el momento de revisar vuestro flujo de CI/CD.


Deja una respuesta