
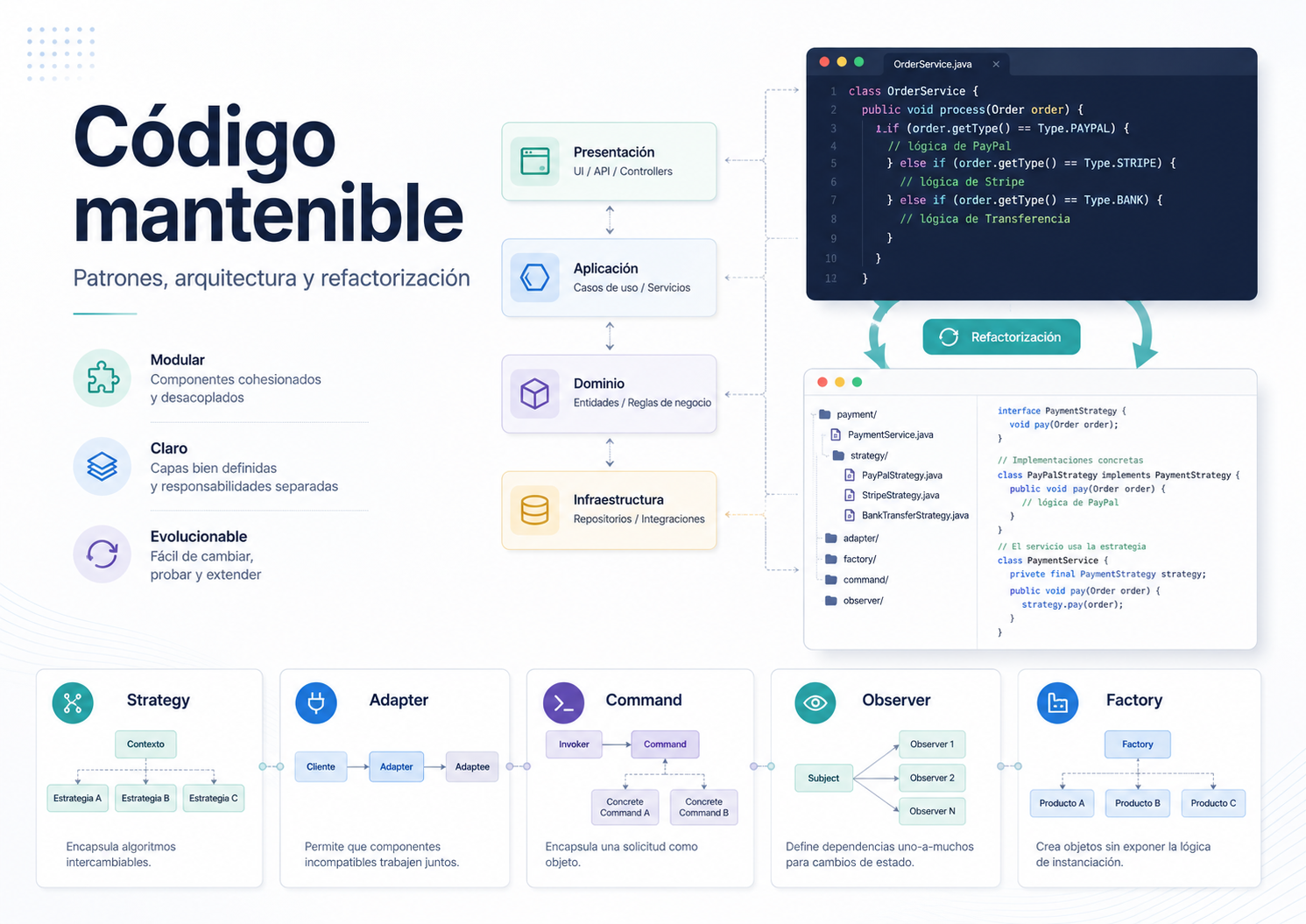
Escribir código mantenible no consiste solo en que una aplicación funcione hoy. Consiste en que otro desarrollador pueda leerla, entenderla, modificarla y evolucionarla dentro de seis meses sin convertir cada cambio en una operación de riesgo.
Qué significa escribir código mantenible
Imagina esta escena: es tu primer día en un proyecto nuevo. Te asignan una tarea que parece sencilla. Solo hay que añadir una funcionalidad a un sistema que ya existe. Abres el código y aparece el problema real: funciones interminables, nombres ambiguos, lógica repetida y piezas que dependen unas de otras de forma caótica.
Avanzas despacio, intentando entender qué hace cada bloque. Cuando por fin logras orientarte, descubres lo peor: cualquier cambio puede romper algo en otra parte del sistema.
A muchos desarrolladores les ha pasado. Por eso conviene recordar una idea básica: escribir código que funciona no basta. El verdadero reto está en construir código claro, modular y sostenible.
El código no solo lo ejecuta una máquina. Lo leen compañeros de equipo, lo revisa tu yo del futuro y, en proyectos medianos o grandes, se convierte en el soporte de decisiones técnicas, evoluciones de producto e integraciones con otros sistemas.
En este artículo veremos cómo los patrones de diseño ayudan a organizar mejor la lógica, por qué la claridad reduce el coste de evolución y cómo un diseño limpio mejora la colaboración, la resiliencia y la mantenibilidad de una arquitectura de software.
Índice de contenidos
- Qué significa escribir código mantenible
- Por qué el código mantenible importa más que el código que funciona
- Patrones de diseño para crear código mantenible
- Cuándo aplicar patrones en código mantenible
- Código mantenible en arquitecturas complejas
- Ejemplos prácticos para refactorizar hacia código mantenible
- Resiliencia y observabilidad en código mantenible
- Checklist de código mantenible
- Recursos para mejorar código mantenible
- Preguntas frecuentes sobre código mantenible
- Conclusión
Por qué el código mantenible importa más que el código que funciona
Una funcionalidad puede pasar todos los tests manuales, desplegarse sin errores y resolver la necesidad inmediata del usuario. Aun así, puede estar mal diseñada. El problema aparece cuando el sistema debe cambiar.
Un código difícil de mantener suele tener señales claras: funciones demasiado largas, clases con demasiadas responsabilidades, condicionales repetidos, nombres poco expresivos, dependencias ocultas, duplicidad de lógica y ausencia de límites claros entre capas.
Al principio, estos problemas parecen pequeños. Pero cada nueva funcionalidad añade más ramificaciones. Cada corrección introduce excepciones. Cada integración externa deja una dependencia más. Y, con el tiempo, el sistema empieza a comportarse como una pieza frágil: cualquier cambio cuesta demasiado y genera miedo.
Por eso, hablar de código mantenible no es hablar de estética. Es hablar de velocidad futura, coste de mantenimiento, calidad técnica, incorporación de nuevos desarrolladores y capacidad real de evolucionar un producto sin reescribirlo cada pocos años.
La mantenibilidad se construye con decisiones pequeñas y constantes: separar responsabilidades, reducir acoplamiento, encapsular variabilidad, nombrar bien las piezas, escribir pruebas útiles y aplicar patrones solo cuando simplifican un problema real.
Patrones de diseño para crear código mantenible
Los patrones de diseño son soluciones conocidas y contrastadas para problemas recurrentes en el desarrollo de software. No son recetas mágicas ni plantillas que deban aplicarse siempre. Son formas de organizar el código para que resulte más comprensible, extensible y fácil de mantener.
Su valor no está solo en la reutilización. También aportan un lenguaje compartido. Cuando un equipo habla de Strategy, Factory, Adapter o Command, no solo está nombrando una técnica: está describiendo una intención de diseño.
Eso mejora las conversaciones técnicas. Permite revisar código con más precisión, discutir alternativas con menos ambigüedad y documentar decisiones sin tener que explicar desde cero cada estructura.
Strategy para código mantenible: encapsular comportamientos intercambiables
El patrón Strategy permite definir una familia de comportamientos y hacerlos intercambiables. Es muy útil cuando una lógica empieza a crecer a base de condicionales y cada nuevo caso obliga a modificar la misma función central.
Por ejemplo, si una aplicación calcula precios según el método de pago, una primera implementación puede ser sencilla:
function calculateFinalPrice(float $price, string $paymentMethod): float
{
if ($paymentMethod === 'credit_card') {
return $price + 0.05;
}
if ($paymentMethod === 'paypal') {
return $price * 1.03;
}
if ($paymentMethod === 'bank_transfer') {
return $price;
}
throw new InvalidArgumentException('Unsupported payment method.');
}El problema aparece cuando se añaden más métodos de pago, reglas por país, promociones, comisiones dinámicas o condiciones especiales. La función empieza a crecer y cada cambio toca el mismo punto crítico.
Con Strategy, cada regla se encapsula en una clase independiente:
<?php
interface PaymentStrategyInterface
{
public function apply(float $price): float;
}
class CreditCardPayment implements PaymentStrategyInterface
{
public function apply(float $price): float
{
return $price + 0.05;
}
}
class PayPalPayment implements PaymentStrategyInterface
{
public function apply(float $price): float
{
return $price * 1.03;
}
}
class BankTransferPayment implements PaymentStrategyInterface
{
public function apply(float $price): float
{
return $price;
}
}
class PriceCalculator
{
public function calculate(float $price, PaymentStrategyInterface $strategy): float
{
return $strategy->apply($price);
}
}El resultado es un código mantenible: cada regla vive en su sitio, se puede probar de forma aislada y añadir una nueva estrategia no obliga a tocar el cálculo principal.
Command para código mantenible: convertir acciones en objetos
El patrón Command encapsula una acción como un objeto independiente. Encaja bien cuando un sistema ejecuta operaciones variadas que comparten una misma forma de invocarse: crear, editar, eliminar, publicar, archivar, enviar o sincronizar.
Una versión basada en condicionales puede funcionar al principio:
def handle_user_action(action, data):
if action == "create":
create_user(data)
elif action == "edit":
edit_user(data)
elif action == "delete":
delete_user(data)Pero cuando aparecen validaciones, permisos, logs, auditoría o eventos posteriores, esa función acaba acumulando demasiada responsabilidad.
Una alternativa más clara consiste en convertir cada acción en una clase:
from abc import ABC, abstractmethod
class UserAction(ABC):
@abstractmethod
def execute(self, data):
pass
class CreateUserAction(UserAction):
def execute(self, data):
print(f"Creating user: {data}")
class EditUserAction(UserAction):
def execute(self, data):
print(f"Editing user: {data}")
class DeleteUserAction(UserAction):
def execute(self, data):
print(f"Deleting user: {data}")
def handle_user_action(action: UserAction, data):
action.execute(data)
handle_user_action(CreateUserAction(), {
"name": "Alice",
"email": "alice@company.net"
})La ventaja no es solo estética. Cada acción tiene una responsabilidad concreta, puede evolucionar sin afectar a las demás y el sistema gana extensibilidad.
Adapter para código mantenible: aislar integraciones externas
El patrón Adapter actúa como puente entre interfaces incompatibles. Es especialmente útil cuando una aplicación necesita integrarse con APIs externas, ERPs, CRMs, LMS, pasarelas de pago, servicios heredados o sistemas que no controlamos.
Sin una capa de adaptación, el código de negocio acaba dependiendo directamente de detalles del proveedor externo: nombres de campos, formatos de respuesta, códigos de error o estructuras de autenticación.
Un adaptador permite esconder esos detalles detrás de una interfaz propia:
<?php
interface StudentRepositoryInterface
{
public function findStudentByEmail(string $email): ?Student;
}
class ExternalLmsStudentAdapter implements StudentRepositoryInterface
{
public function __construct(private ExternalLmsClient $client) {}
public function findStudentByEmail(string $email): ?Student
{
$response = $this->client->searchUser([
'mail' => $email,
]);
if (!$response['found']) {
return null;
}
return new Student(
email: $response['data']['mail'],
name: $response['data']['full_name']
);
}
}Así, si mañana cambia el proveedor externo, el impacto queda concentrado en el adaptador. El dominio de la aplicación sigue hablando su propio lenguaje.
Observer para código mantenible: reaccionar a eventos sin acoplarlo todo
El patrón Observer permite que varias piezas reaccionen a un evento sin que el emisor conozca todos los detalles de lo que ocurrirá después.
Por ejemplo, cuando un usuario completa un curso, puede ser necesario enviar una notificación, generar una insignia, actualizar analíticas y registrar una auditoría. Si todo eso se ejecuta dentro del mismo método, el código se vuelve rígido y difícil de probar.
Un enfoque basado en eventos permite separar responsabilidades:
<?php
class CourseCompletedEvent
{
public function __construct(
public readonly int $userId,
public readonly int $courseId
) {}
}
class SendCompletionEmailListener
{
public function __invoke(CourseCompletedEvent $event): void
{
// Enviar email al estudiante.
}
}
class AwardBadgeListener
{
public function __invoke(CourseCompletedEvent $event): void
{
// Emitir insignia o certificado.
}
}Este tipo de diseño ayuda a crear código mantenible porque cada reacción al evento puede crecer de forma independiente.
Factory para código mantenible: centralizar la creación de objetos
El patrón Factory delega la creación de objetos en una pieza especializada. Es útil cuando construir un objeto implica reglas, configuración, dependencias o decisiones que no deberían estar repartidas por toda la aplicación.
Una fábrica no mejora el código por existir. Aporta valor cuando evita duplicidad, reduce conocimiento disperso y centraliza decisiones de construcción.
<?php
class ReportExporterFactory
{
public function create(string $format): ReportExporterInterface
{
return match ($format) {
'pdf' => new PdfReportExporter(),
'csv' => new CsvReportExporter(),
'xlsx' => new XlsxReportExporter(),
default => throw new InvalidArgumentException('Unsupported format.'),
};
}
}El cliente no necesita saber cómo se construye cada exportador. Solo pide el formato que necesita y trabaja contra una interfaz común.
Cuándo aplicar patrones en código mantenible y cuándo evitarlos
Los patrones de diseño no deben introducirse por estética, por moda ni para demostrar conocimiento técnico. Tienen sentido cuando reducen complejidad real.
Un buen diseño no consiste en acumular patrones. Consiste en elegir la solución adecuada con el menor nivel de complejidad posible.
Hay una regla práctica que suele funcionar: si el patrón hace que el próximo cambio sea más fácil, probablemente aporta valor. Si solo añade clases, interfaces y abstracciones que nadie necesita todavía, probablemente estás anticipando problemas que quizá no lleguen.
Aplicar un patrón tiene sentido cuando:
- La lógica empieza a crecer con demasiados condicionales.
- Hay varias implementaciones de una misma regla.
- Necesitas desacoplar el dominio de proveedores externos.
- Quieres probar piezas de forma aislada.
- Hay cambios frecuentes en una parte concreta del sistema.
- El equipo necesita un lenguaje común para hablar de diseño.
Conviene evitarlo cuando el problema es simple, el cambio no está justificado o la abstracción añade más dificultad que claridad. El objetivo siempre debe ser el mismo: crear código mantenible, no código más sofisticado.
Código mantenible en arquitecturas complejas
En sistemas grandes, distribuidos o con años de evolución a sus espaldas, el código deja de ser un detalle de implementación y pasa a convertirse en parte esencial de la arquitectura.
Si esa base es opaca, rígida o confusa, cualquier intento de evolucionar el sistema se vuelve caro, lento y arriesgado. Esto se nota especialmente en aplicaciones con muchas integraciones, equipos grandes, lógica de negocio cambiante o dependencias heredadas.
Arquitectura y código mantenible: facilitar la evolución del sistema
Todo sistema complejo cambia. Cambian los requisitos, cambian las prioridades del negocio y cambian también las integraciones, los equipos y la escala del producto.
La única forma razonable de acompañar ese cambio es partir de un código claro, desacoplado y con responsabilidades bien delimitadas.
Cuando las piezas están bien separadas, el sistema puede evolucionar por partes. Puedes sustituir una integración, cambiar una regla de negocio, mejorar una pantalla o extraer un servicio sin tener que reescribirlo todo.
Refactorización y código mantenible: reducir el riesgo técnico
Refactorizar no es una actividad excepcional. Forma parte del ciclo natural de cualquier producto vivo. Pero en código poco claro, cada refactorización se parece demasiado a una apuesta.
Un código mantenible permite refactorizar con más seguridad porque las responsabilidades están acotadas, las dependencias son explícitas y las pruebas pueden cubrir comportamientos relevantes.
Esto no elimina el riesgo, pero lo reduce. Y reducir riesgo técnico es una de las mejores formas de proteger la velocidad del equipo.
Código mantenible para mejorar la colaboración en equipos grandes
En equipos amplios, la calidad del código influye directamente en la capacidad de colaboración. Un diseño claro reduce el tiempo de onboarding, mejora las conversaciones técnicas y permite que varias personas trabajen en paralelo con menos interferencias.
Esto se vuelve especialmente evidente cuando el sistema combina tecnologías distintas, arrastra dependencias heredadas o integra servicios externos que no siempre están bien documentados.
Un equipo no escala solo contratando más personas. Escala cuando la arquitectura permite que esas personas entiendan el sistema, aporten cambios y revisen código sin depender siempre de una única persona que conoce todos los detalles.
Ejemplos prácticos para refactorizar hacia código mantenible
La teoría es útil, pero la mantenibilidad se entiende mejor con ejemplos. Veamos tres casos frecuentes: condicionales repetidos, integraciones rígidas y configuraciones variables según perfil.
Código mantenible en inventario: de condicionales a Strategy
Pensemos en una aplicación Symfony conectada con un ERP. Si toda la lógica de inventario vive dentro de un controlador, el código puede funcionar, pero resulta difícil de mantener:
class InventoryController extends AbstractController
{
public function processStock(string $type, int $quantity): Response
{
$erpService = new ERPService();
if ($type === 'finished') {
$erpService->callProcedure('reserve_finished_goods', [
'quantity' => $quantity
]);
return new Response("Reservando $quantity productos terminados.");
}
if ($type === 'rma') {
$erpService->callProcedure('inspect_rma_products', [
'quantity' => $quantity
]);
return new Response("Inspeccionando $quantity devoluciones.");
}
if ($type === 'raw') {
$erpService->callProcedure('check_raw_material_availability', [
'quantity' => $quantity
]);
return new Response("Verificando $quantity unidades de materia prima.");
}
return new Response('Tipo de inventario desconocido.');
}
}El controlador conoce demasiados detalles: tipos de inventario, nombres de procedimientos, mensajes de respuesta y creación del servicio ERP. Una refactorización con Strategy permite separar cada comportamiento:
interface InventoryStrategy
{
public function process(int $quantity): string;
}
class FinishedGoodsStrategy implements InventoryStrategy
{
public function __construct(private ERPService $erpService) {}
public function process(int $quantity): string
{
$this->erpService->callProcedure('reserve_finished_goods', [
'quantity' => $quantity
]);
return "Reservando $quantity productos terminados.";
}
}
class RawMaterialStrategy implements InventoryStrategy
{
public function __construct(private ERPService $erpService) {}
public function process(int $quantity): string
{
$this->erpService->callProcedure('check_raw_material_availability', [
'quantity' => $quantity
]);
return "Verificando $quantity unidades de materia prima.";
}
}La mejora es inmediata: cada estrategia se entiende de forma aislada, la lógica de negocio deja de estar enterrada en condicionales y el equipo puede repartir trabajo por dominios sin estorbarse continuamente.
Código mantenible en dashboards: estrategias por perfil
En una aplicación educativa, no todos los usuarios ven lo mismo. Estudiantes, docentes, coordinadores o personal administrativo pueden requerir menús, permisos, colores, accesos y configuraciones distintas.
Si toda esa lógica se reparte entre frontend, controladores y condicionales, el sistema se vuelve difícil de razonar. Una solución más clara consiste en encapsular la configuración por perfil mediante estrategias.
interface DashboardStrategy
{
public function getLogo(): string;
public function getColors(): array;
public function getMenu(): array;
}
class StudentDashboardStrategy implements DashboardStrategy
{
public function __construct(private Institution $institution) {}
public function getLogo(): string
{
return $this->institution->logo;
}
public function getColors(): array
{
return $this->institution->colors;
}
public function getMenu(): array
{
return ['profile', 'schedule', 'grades'];
}
}
class TeacherDashboardStrategy implements DashboardStrategy
{
public function __construct(private Institution $institution) {}
public function getLogo(): string
{
return $this->institution->logo;
}
public function getColors(): array
{
return $this->institution->colors;
}
public function getMenu(): array
{
return ['profile', 'classes', 'attendance'];
}
}Este diseño permite que el backend devuelva una configuración ya resuelta y que el frontend se limite a representarla. El resultado es más predecible, más fácil de probar y más preparado para crecer.
Código mantenible en integraciones: proteger el dominio con Adapter
Otro caso habitual aparece cuando una aplicación depende de un servicio externo. Si el código de negocio llama directamente a la API, cualquier cambio del proveedor puede afectar a muchas zonas del sistema.
Una capa de adaptación permite proteger el dominio:
interface BadgeIssuerInterface
{
public function issueBadge(int $userId, string $badgeCode): void;
}
class ExternalBadgeProviderAdapter implements BadgeIssuerInterface
{
public function __construct(private ExternalBadgeClient $client) {}
public function issueBadge(int $userId, string $badgeCode): void
{
$this->client->sendAward([
'recipient_id' => $userId,
'achievement' => $badgeCode,
'issued_at' => date('c'),
]);
}
}La aplicación trabaja con BadgeIssuerInterface. El proveedor externo queda encapsulado. Si mañana cambia la API, el impacto se concentra en el adaptador.
Resiliencia y observabilidad en código mantenible
El código mantenible no solo ayuda a desarrollar más rápido. También hace que el sistema sea más resistente al cambio y más fácil de observar en producción.
Cuando las responsabilidades están separadas, es más sencillo añadir logs, métricas, trazas, alertas o eventos de dominio sin mezclarlo todo con la lógica principal.
Por ejemplo, una acción importante puede emitir un evento de dominio, y diferentes listeners pueden encargarse de registrar auditoría, enviar notificaciones o alimentar un sistema de analítica.
class UserRegisteredEvent
{
public function __construct(
public readonly int $userId,
public readonly string $email
) {}
}
class AuditUserRegistrationListener
{
public function __invoke(UserRegisteredEvent $event): void
{
// Registrar auditoría.
}
}
class SendWelcomeEmailListener
{
public function __invoke(UserRegisteredEvent $event): void
{
// Enviar email de bienvenida.
}
}En muchos casos, esa capa de observabilidad acaba generando una de las fuentes de valor más importantes del proyecto: datos reales sobre cómo se comporta el sistema.
Esos datos permiten priorizar mejor, justificar decisiones técnicas y anticipar cuellos de botella antes de que se conviertan en incidencias graves.
¿Necesitas mejorar un código difícil de mantener?
Si tu aplicación ha crecido durante años, acumula deuda técnica o cada cambio requiere demasiado contexto, puede que necesites algo más que pequeños ajustes: una revisión de arquitectura, una estrategia de refactorización y criterios claros para reducir acoplamiento sin parar el producto.
Puedo ayudarte a analizar tu base de código, detectar puntos críticos y definir un plan realista para mejorar mantenibilidad, modularidad y evolución técnica.
Checklist de código mantenible
Una forma práctica de revisar la mantenibilidad de una base de código es hacerse preguntas concretas. No hace falta resolverlo todo de golpe, pero sí conviene detectar dónde están los principales puntos de fricción.
Señales de código mantenible
- Las clases tienen responsabilidades claras.
- Los métodos son relativamente cortos y expresan una intención concreta.
- La lógica de negocio no está mezclada con detalles de infraestructura.
- Las integraciones externas están encapsuladas.
- Las reglas cambiantes están aisladas.
- Hay interfaces útiles, no abstracciones artificiales.
- El equipo puede modificar una zona sin entender todo el sistema.
- Existen pruebas para comportamientos críticos.
- Los errores importantes dejan trazas comprensibles.
- La arquitectura se puede explicar con un diagrama sencillo.
Señales de código poco mantenible
- Cualquier cambio obliga a tocar muchos archivos sin relación aparente.
- Hay funciones con demasiados condicionales y casos especiales.
- Los controladores contienen lógica de negocio compleja.
- La misma regla aparece duplicada en varias zonas.
- Las clases dependen directamente de APIs externas.
- Solo una persona del equipo entiende ciertas partes del sistema.
- El miedo a romper producción bloquea la refactorización.
- Las pruebas son escasas, frágiles o demasiado acopladas a detalles internos.
- Los nombres no explican la intención del código.
- La documentación no refleja cómo funciona realmente el sistema.
La clave no está en tener una base de código perfecta. La clave está en saber dónde estás, qué duele más y qué mejoras tendrán más impacto sobre la evolución del producto.
Recursos para mejorar código mantenible
Para seguir profundizando en código mantenible, patrones de diseño y refactorización, estos recursos son especialmente útiles:
Lecturas sobre código mantenible y refactorización
- Clean Code, de Robert C. Martin. Un clásico sobre legibilidad, mantenibilidad y disciplina en el desarrollo.
- Design Patterns: Elements of Reusable Object-Oriented Software, de Gamma, Helm, Johnson y Vlissides. La referencia histórica sobre patrones de diseño.
- Refactoring, de Martin Fowler. Una guía fundamental para mejorar código existente sin romper su comportamiento.
- Refactoring Guru: Design Patterns. Recurso visual y práctico para entender patrones de diseño con ejemplos.
Herramientas para analizar código mantenible
- SonarQube, útil para análisis estático, detección de code smells y seguimiento de deuda técnica.
- PHPStan, herramienta de análisis estático para detectar errores y mejorar calidad en proyectos PHP.
- Psalm, otra herramienta potente de análisis estático para PHP.
- Draw.io, práctico para documentar arquitectura, flujos y diagramas sin fricción.
- GitHub Copilot, útil para acelerar tareas repetitivas, siempre con revisión técnica y criterio de arquitectura.
Preguntas frecuentes sobre código mantenible
¿Qué es código mantenible?
Es código que puede entenderse, modificarse, probarse y evolucionarse con un coste razonable. No se trata solo de que funcione, sino de que siga siendo útil cuando cambian los requisitos.
¿Qué diferencia hay entre código limpio y código mantenible?
El código limpio suele centrarse en legibilidad, nombres, tamaño de funciones y claridad local. El código mantenible incluye eso, pero también arquitectura, desacoplamiento, pruebas, modularidad y capacidad de evolución.
¿Cuándo conviene aplicar patrones de diseño?
Cuando ayudan a resolver un problema real: eliminar condicionales repetidos, aislar integraciones externas, encapsular reglas cambiantes o hacer que una parte del sistema sea más extensible.
¿Qué patrón ayuda a eliminar condicionales repetidos?
Depende del caso, pero Strategy suele funcionar muy bien cuando hay varias reglas intercambiables. Command encaja mejor cuando hay acciones independientes que comparten una forma común de ejecutarse.
¿Cómo saber si una base de código tiene deuda técnica?
Algunas señales claras son funciones demasiado largas, duplicidad, acoplamiento alto, miedo a modificar, falta de pruebas, integraciones mezcladas con lógica de negocio y dependencia excesiva de conocimiento tribal.
¿Cómo empezar a refactorizar código legado sin romper producción?
Empieza por caracterizar el comportamiento actual, añadir pruebas donde sea posible, identificar puntos de alto impacto y aplicar cambios pequeños. Refactorizar no debería ser una reescritura impulsiva, sino una estrategia incremental.
Conclusión: el código mantenible es una decisión de ingeniería
Escribir código que otros puedan entender no es un gesto de estilo ni una manía de desarrollador meticuloso. Es una decisión de ingeniería.
Es lo que permite que un sistema evolucione sin colapsar, que un equipo crezca sin perder velocidad y que una base de código siga siendo útil dentro de seis meses, de dos años o de una reestructuración completa del producto.
La claridad del código no consiste solo en elegir buenos nombres o dividir funciones largas. Tiene que ver con diseñar bien las responsabilidades, encapsular la variabilidad, reducir el acoplamiento y construir piezas que puedan cambiar sin arrastrar al resto del sistema.
Ahí es donde patrones como Strategy, Adapter, Observer o Command dejan de ser teoría y se convierten en herramientas prácticas.
Y hay una idea final que conviene no perder de vista: el código no se escribe solo para resolver el problema de hoy. También se escribe para que otra persona —o tú mismo dentro de unos meses— pueda entenderlo, modificarlo y seguir construyendo sobre él.
Cuando se trabaja así, el software deja de ser una acumulación de soluciones rápidas y empieza a parecerse mucho más a una arquitectura sostenible.


Deja una respuesta