
En el mundo del desarrollo de software, la automatización de despliegues con GitLab CI/CD se ha convertido en una solución indispensable para equipos que buscan optimizar su flujo de trabajo. Imagina un escenario en el que, debido a la dependencia de una sola persona para realizar despliegues manuales, todo el equipo se ve paralizado porque esa persona no puede conectarse al servidor. Esto fue exactamente lo que nos sucedió a nosotros, y fue el detonante para adoptar una herramienta de integración y despliegue continuo (CI/CD) que nos permitiera trabajar de manera más eficiente y colaborativa.
La automatización de procesos con GitLab CI/CD no solo resolvió nuestros problemas de despliegues manuales, sino que también nos ayudó a reducir errores, acelerar la entrega de nuevas funcionalidades y mejorar la calidad del software. Con GitLab CI/CD, logramos crear pipelines que automatizan desde la integración del código hasta el despliegue en producción, eliminando cuellos de botella y permitiendo que todos los miembros del equipo participen activamente en el proceso.
En este artículo, te cuento cómo implementamos esta solución en mi empresa – para varios de los proyectos que tenemos para un cliente importante -, los desafíos que superamos y las mejores prácticas que aprendimos en el camino. Si tu equipo aún depende de despliegues manuales o enfrenta problemas similares, esta guía te mostrará cómo GitLab CI/CD puede transformar tu flujo de trabajo. Descubre cómo la automatización de despliegues con GitLab CI/CD no solo optimiza tus procesos, sino que también fomenta la colaboración y la eficiencia en equipos de desarrollo.
Tabla de contenidos
Cómo el CI/CD nos salvó de un caos en los despliegues: Una historia de equipo
Hace unos meses, mi equipo y yo nos enfrentamos a un problema que muchos desarrolladores conocen demasiado bien: los despliegues manuales. Para el proyecto que nos ocupa – que es una aplicación PWA desarrollada en base PHP con Laravel para el backend y Tailwind/VueJS para el frontend – y en el que somos un equipo pequeño de cuatro personas, y yo era el único con acceso al servidor del cliente para desplegar nuestros cambios. Esto, que en un principio parecía una ventaja (¡al menos yo tenía el control total!), se convirtió en un cuello de botella que casi nos cuesta un proyecto importante.
Todo comenzó un día en el que, por razones ajenas a mi voluntad, no pude conectarme al servidor del cliente. Habíamos terminado un sprint con varias funcionalidades críticas listas para ser desplegadas, pero no había manera de que yo accediera al servidor para hacerlo. El cliente estaba impaciente, y mi equipo no podía hacer nada más que esperar. Fue en ese momento cuando nos dimos cuenta de que necesitábamos una solución mejor: CI/CD.
Desafíos de los despliegues manuales: Dependencia, errores y falta de control
Antes de implementar CI/CD, nuestros despliegues eran un proceso manual y propenso a errores. A continuación te cuento algunos de los problemas a los que nos enfrentábamos:
- Dependencia de una sola persona: Como yo era el único con acceso al servidor, cualquier problema que me impidiera desplegar (como la falta de conexión) paralizaba todos los entregables al cliente y el equipo tampoco podía actuar porque sólo disponemos de un acceso VPN nominal a mi nombre y usuario.
- Riesgo de desplegar código incorrecto: En una ocasión, un compañero subió un cambio que no había sido probado completamente. Confiando en su palabra, lo desplegué directamente a producción. El resultado: parte de la funcionalidad de validaciones de alumnos, del producto dejó de funcionar …por unas horas. Hasta que el cliente nos contactó e indicó que no podía pasar lista en clase con nuestro recién estrenado producto. Fue un error reputacional, de cara al cliente, que nos enseñó una lección valiosa.
- Falta de control sobre los entornos: No teníamos pipelines separados para los diferentes entornos (pre, staging y producción). Esto significaba que cualquier error en el código podía afectar directamente al entorno del cliente.
Estos problemas nos llevaron a buscar una solución que no solo automatizara los despliegues, sino que también redujera los riesgos y permitiera a todos los miembros del equipo participar en el proceso.
¿Qué es CI/CD? Beneficios de la automatización de despliegues para equipos de desarrollo
La Integración Continua (CI) es una práctica que consiste en integrar cambios de código en un repositorio compartido de manera frecuente. Esto permite detectar errores rápidamente, ya que cada cambio se prueba automáticamente antes de ser fusionado con el código principal. Por otro lado, el Despliegue Continuo (CD) se enfoca en automatizar el proceso de llevar esos cambios a producción, lo que garantiza que las nuevas funcionalidades lleguen a los usuarios de manera rápida y segura.
La combinación de CI/CD ofrece múltiples beneficios:
- Reduce errores humanos: Al automatizar tareas repetitivas, como la ejecución de pruebas o el despliegue, se minimiza el riesgo de errores.
- Acelera el tiempo de entrega: Los cambios pueden llegar a producción en cuestión de minutos, en lugar de días o semanas.
- Mejora la calidad del software: Las pruebas automatizadas garantizan que el código funcione correctamente antes de ser desplegado.
- Facilita la colaboración: Los equipos pueden trabajar de manera más eficiente, ya que todos los cambios se integran y prueban de manera continua.
Si quieres aprender más sobre los conceptos básicos de CI/CD, te recomiendo este artículo de Red Hat.
Gitlab CI/CD
GitLab CI/CD es una herramienta integrada en la plataforma GitLab que permite automatizar el proceso de Integración Continua (CI) y Despliegue Continuo (CD). Aquí te explico cómo funciona paso a paso:
1. Integración Continua (CI):
- ¿Qué es?: La Integración Continua es una práctica en la que los desarrolladores integran su código en un repositorio compartido varias veces al día. Cada vez que se realiza un cambio, se ejecutan pruebas automatizadas para asegurarse de que el nuevo código no rompa la aplicación.
- Cómo funciona en GitLab:
- Cuando un desarrollador hace un
pushde código a una rama (por ejemplo,feature-branch), GitLab detecta el cambio y activa automáticamente un pipeline. - El pipeline es una serie de jobs (tareas) que se ejecutan en secuencia. Estos jobs pueden incluir:
- Build: Compilar el código o preparar los archivos necesarios.
- Test: Ejecutar pruebas unitarias, de integración o de extremo a extremo.
- Lint: Verificar la calidad del código (por ejemplo, con herramientas como ESLint o PHP_CodeSniffer).
- Si todas las pruebas pasan correctamente, el código puede fusionarse en la rama principal (
mainodevelop).
- Cuando un desarrollador hace un
2. Despliegue Continuo (CD):
- ¿Qué es?: El Despliegue Continuo es el proceso de llevar automáticamente el código validado a los entornos de staging o producción, sin necesidad de intervención manual.
- Cómo funciona en GitLab:
- Una vez que el código ha pasado las pruebas en la etapa de CI, el pipeline puede continuar con la etapa de despliegue.
- GitLab permite configurar diferentes entornos (por ejemplo,
stagingyproducción) y definir reglas para cuándo y cómo se despliega el código en cada uno. - Por ejemplo, puedes configurar que el código solo se despliegue en producción después de que se haya fusionado en la rama
mainy haya sido aprobado por un revisor.
3. Componentes clave de GitLab CI/CD:
Reglas y condiciones: Puedes definir reglas para controlar cuándo se ejecutan los jobs. Por ejemplo, puedes hacer que un job solo se ejecute en la rama main o cuando se crea un Merge Request.
.gitlab-ci.yml: Este es el fichero de configuración que define cómo funciona el pipeline. En él, especificas las etapas (stages), los jobs y las reglas para ejecutarlos.
GitLab Runner: Es un agente que ejecuta los jobs definidos en el pipeline. Puede estar instalado en un servidor local, en la nube o incluso en un contenedor Docker.
Variables de entorno: GitLab permite definir variables de entorno (como credenciales o URLs de servidores) que se pueden usar en los jobs sin exponer información sensible.
4. Ejemplo de un pipeline básico:
Un pipeline típico en GitLab podría tener las siguientes etapas:
- build: Compilar el código y preparar los archivos.
- test: Ejecutar pruebas automatizadas.
- deploy: Desplegar el código en un entorno específico (staging o producción).
Aquí tienes un ejemplo simplificado de un fichero de configuración o Pipeline .gitlab-ci.yml:
stages:
- build
- test
- deploy
build_job:
stage: build
script:
- echo "Compilando el código..."
- npm install
- npm run build
test_job:
stage: test
script:
- echo "Ejecutando pruebas..."
- npm test
deploy_staging:
stage: deploy
script:
- echo "Desplegando en staging..."
- npm run deploy:staging
only:
- mainLa solución: Cómo implementamos la automatización de despliegues con GitLab CI/CD
En nuestra empresa utilizamos Gitlab como sistema de control de versiones on-premises, por lo que ya teníamos Gitlab CI/CD integrado así que sólo nos quedaba configurarlo para que funcionara correctamente.
Configuración de pipelines para pre, staging y producción
Lo primero que hicimos fue configurar pipelines separados para cada entorno:
- Pre: Para pruebas iniciales y verificación de cambios.
- Staging: Para pruebas más exhaustivas y aprobación del cliente.
- Producción: Para el despliegue final.
Cada pipeline tienes sus propias reglas y validaciones. Por ejemplo, el pipeline de producción solo se activa cuando se fusionaba código en la rama develop, y requiere la aprobación de al menos dos miembros del equipo.
Automatización de despliegues: Eliminando cuellos de botella
Configuramos GitLab CI/CD para que cualquier miembro del equipo pudiera desplegar una rama directamente a los entornos de pre o staging. Esto eliminó la dependencia de una sola persona y permitió que todos contribuyeran de manera más eficiente.
Por ejemplo, si alguien quería probar un cambio en el entorno de staging, solo necesitaba hacer un push a la rama staging y el pipeline se encargaba del resto. Ya no tenían que esperar a que yo estuviera disponible.
Pruebas automatizadas: Garantizando la calidad del código
Implementamos pruebas automatizadas en cada pipeline para asegurarnos de que el código funcionara correctamente antes de ser desplegado. Esto incluía:
- Pruebas unitarias.
- Pruebas de integración.
- Verificación de la construcción de assets (como los de Tailwind CSS y Vue.js).
Si alguna prueba fallaba, el pipeline se detenía y notificaba al equipo. Esto nos ayudó a evitar desplegar código defectuoso a producción.
Resultados de la automatización: Eficiencia, colaboración y menos errores
La implementación de CI/CD no solo resolvió nuestros problemas de despliegues, sino que también mejoró la colaboración en el equipo. Ahora, cualquier miembro puede desplegar cambios sin depender de una sola persona, y tenemos la tranquilidad de saber que cada cambio pasa por un proceso de validación antes de llegar a producción.
Además, los errores en producción se redujeron drásticamente. Gracias a las pruebas automatizadas y los pipelines separados, podemos detectar y corregir problemas antes de que afecten al cliente.
Cómo configurar GitLab CI/CD: Creación del fichero .gitlab-ci.yml
GitLab es una plataforma que no solo te permite gestionar tu código, sino también automatizar flujos de trabajo mediante su herramienta integrada de CI/CD. Para comenzar, necesitas crear un fichero llamado .gitlab-ci.yml en la raíz de tu repositorio. Este fichero es el corazón de tu pipeline y define qué tareas se ejecutarán y en qué orden.
La estructura básica de un fichero .gitlab-ci.yml incluye:
stages: Define las etapas del pipeline. Por ejemplo, puedes tener etapas para clonar el repositorio, ejecutar pruebas y desplegar la aplicación.jobs: Define las tareas que se ejecutan en cada etapa. Cada job tiene un nombre y un conjunto de instrucciones que se ejecutan en orden.
A continuación, te mostraré un ejemplo práctico basado en un proyecto real, para que puedas ver cómo funciona todo esto en la práctica.
Instalación y configuración de GitLab Runner en Ubuntu
Antes de poder ejecutar pipelines de CI/CD, es necesario configurar un GitLab Runner en un servidor. Un GitLab Runner es un agente que ejecuta los jobs definidos en tu fichero .gitlab-ci.yml. Para instalarlo en un servidor Ubuntu, sigue estos pasos:
1. Actualiza el sistema operativo:
Asegúrate de que tu servidor esté actualizado ejecutando, tiene los últimos parches y dependencias actualizadas.
sudo apt update && sudo apt upgrade -y2. Instala Gitlab Runner:
Agrega el repositorio oficial de GitLab e instala el Runner:
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh | sudo bash
sudo apt install gitlab-runner3. Registra el Runner:
Una vez instalado, registra el Runner en tu proyecto de GitLab. Ejecuta el siguiente comando y sigue las instrucciones:
sudo gitlab-runner registerDurante el registro, se te pedirá:
- La URL de tu instancia de GitLab.
- Un token de registro (que puedes encontrar en la sección CI/CD de tu proyecto en GitLab).
- Una descripción y etiquetas para el Runner.
- El ejecutor (por ejemplo,
shellodocker).
4. Inicia e Runner:
Una vez registrado, inicia el servicio:
sudo gitlab-runner start5. Verifica el estado del Runner:
Asegúrate de que el Runner está activo y funcionando:
sudo gitlab-runner statusCon estos pasos, tu servidor Ubuntu estará listo para ejecutar pipelines de CI/CD utilizando GitLab Runner.
Pipeline en acción: Ejemplo práctico para un proyecto Laravel con Tailwind CSS y Vue.js
En este ejemplo, vamos a configurar un pipeline para un proyecto Laravel que utiliza Tailwind CSS para los estilos y Vue.js para la interactividad del frontend, además, el proyecto está desplegado en una arquitectura Docker, que incluye contenedor de base de datos MySQL, contenedor de Apache2 y contenedor de PHP-FPM.
El pipeline consta de tres etapas principales: pull_code (para clonar el repositorio), test (para ejecutar pruebas) y deploy_app (para desplegar la aplicación).
Aquí está el fichero .gitlab-ci.yml.
Nota: Por privacidad, se han eliminado referencias al cliente y producto y reemplazadas por «myApp»
stages:
- pull_code
- test
- deploy_app
pull_code:
stage: pull_code
script:
- git -C /opt/myapp pull https://$GIT_USERNAME:$GIT_PAT@source.example.com/myorg/myapp.git main
artifacts:
paths:
- /opt/myapp
only:
- main # Solo se ejecuta en la rama 'main'
tags:
- ubuntu # Se ejecuta en un runner con la etiqueta 'ubuntu'
test:
stage: test
script:
- echo "Ejecutando pruebas de Laravel..."
# Ejecuta pruebas unitarias de Laravel
- docker exec -t php-container bash -c "cd /var/www/html && php artisan test"
only:
- main
tags:
- ubuntu
deploy_app:
stage: deploy_app
script:
- echo "Desplegando aplicación..."
# Verifica si el contenedor de PHP está en ejecución
- docker ps | grep php-container || echo "El contenedor de PHP no está en ejecución"
# Ejecuta composer dumpautoload dentro del contenedor
- docker exec -t php-container bash -c "cd /var/www/html && composer dumpautoload"
# Ejecuta migraciones de Laravel dentro del contenedor
- docker exec -t php-container bash -c "cd /var/www/html && php artisan migrate"
# Compila el frontend, ejecuta NPM dentro del contenedor
- docker exec -t php-container bash -c "cd /var/www/html && npm run build"
only:
- main # Solo se ejecuta en la rama 'main'
tags:
- ubuntu # Se ejecuta en un runner con la etiqueta 'ubuntu'Explicación detallada:
pull_code:- Clona el repositorio en un directorio específico (
/opt/myapp). - Guarda el contenido clonado como un artefacto, lo que significa que estará disponible para las siguientes etapas.
- Clona el repositorio en un directorio específico (
test:- Pruebas de Laravel: Ejecuta las pruebas unitarias de Laravel utilizando el comando
php artisan test.
- Pruebas de Laravel: Ejecuta las pruebas unitarias de Laravel utilizando el comando
deploy_app:- Verifica si el contenedor Docker
php-containerestá en ejecución. - Ejecuta comandos dentro del contenedor para:
- actualizar dependencias (
composer dumpautoload) - ejecutar migraciones (
php artisan migrate) - construir los assets del frontend (
npm run build).
- actualizar dependencias (
- Verifica si el contenedor Docker
Una vez configurado nuestro fichero de pipeline, lo añadiremos a la configuración de CI/CD de nuestro repositorio. Para ello accederemos dentro de nuestro repositorio, al menú Build y ahí en la opción Pipeline editor . Seleccionaremos entonces la rama sobre la que queremos aplicar CI/CD e introduciremos nuestro código YAML en el editor.
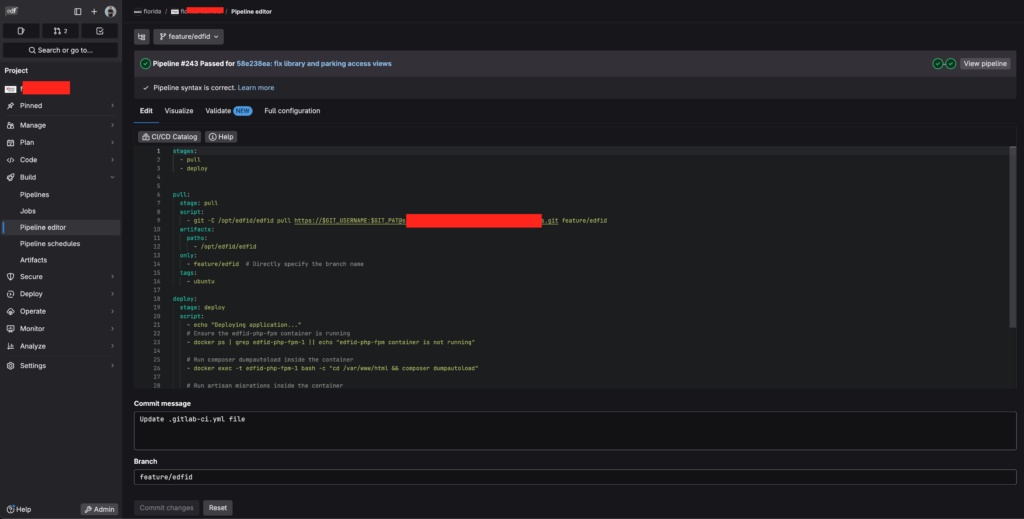
El pipeline anteriormente descrito mediante YAML puede expresarse de forma gráfica así

Gestión segura de variables de entorno en GitLab CI/CD
Las variables de entorno son una parte fundamental de cualquier pipeline de CI/CD, ya que permiten almacenar información sensible (como credenciales o tokens) y configuraciones específicas del entorno. En nuestro caso, debido a la configuración del repositorio GIT, que se debe utilizar mediante PAT ( Personal Access Token ), necesitamos que nuestros Pipelines de CI/CD incluyan la configuración necesaria en forma de variable de entorno, para poder hacer pull del repositorio.
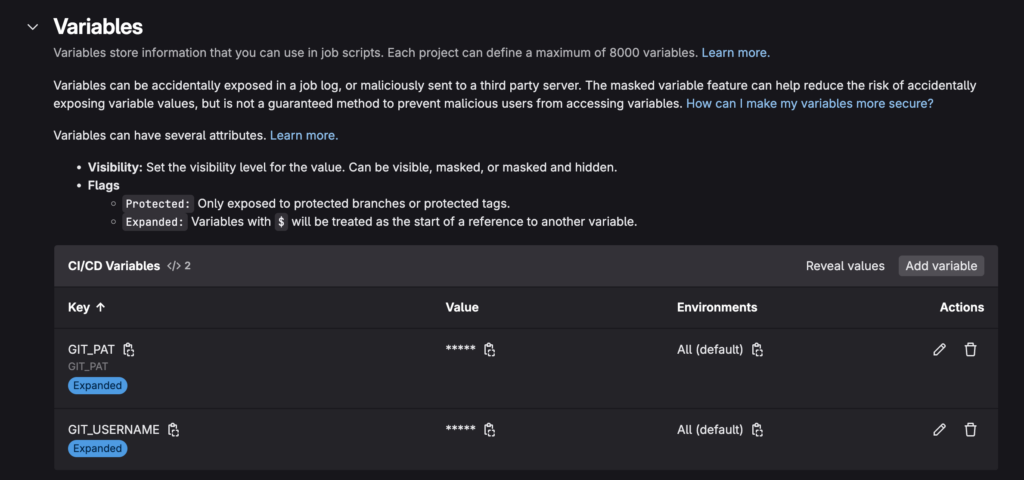
En GitLab, puedes definir variables de entorno de dos maneras:
1. Variables de entorno a nivel de proyecto
Estas variables están disponibles solo para el proyecto en el que se definen.
Para configurarlas:
- 1. Ve a la sección CI/CD de tu proyecto en Gitlab.
- 2. Haz click en variables
- 3. Agrega dos nuevas variables con nombre y un valor.
Por ejemplo:- Variable 1, para el usuario de GIT:
- Nombre:
GIT_USERNAME - Valor:
mi_usuario_de_gitlab
- Nombre:
- Variable 2, para el PAT de GIT:
- Nombre:
GIT_PAT - Valor: mi_token_pat_gitlab
- Nombre:
- Variable 1, para el usuario de GIT:
2. Variables de entorno a nivel de grupo o instancia
Estas variables están disponibles para todos los proyectos dentro de un grupo o instancia de GitLab. Son útiles para configuraciones compartidas, como credenciales de acceso a servicios comunes.
Uso de variables de entorno en el pipeline
Una vez definidas, puedes usar las variables de entorno en tu fichero .gitlab-ci.yml. Por ejemplo:
pull_code:
stage: pull_code
script:
- git -C /opt/myapp pull https://$GIT_USERNAME:$GIT_PAT@source.example.com/myorg/myapp.git main
artifacts:
paths:
- /opt/myapp
only:
- main # Solo se ejecuta en la rama 'main'
tags:
- ubuntu # Se ejecuta en un runner con la etiqueta 'ubuntu'
Protección de variables sensibles
GitLab permite marcar variables como protegidas o enmascaradas:
- Protegidas: Solo están disponibles en pipelines que se ejecutan en ramas protegidas (como
mainoproduction). - Enmascaradas: Su valor no se muestra en los logs del pipeline, lo que las hace ideales para contraseñas o tokens.
Para marcar una variable como protegida o enmascarada, simplemente activa las opciones correspondientes al crearla en la interfaz de GitLab.
Activación de pipelines y jobs: Reglas y condiciones en GitLab CI/CD
Una de las ventajas de GitLab CI/CD es su flexibilidad para definir cuándo y cómo se ejecutan las pipelines y los jobs. Esto se controla mediante reglas y directivas en el fichero .gitlab-ci.yml. A continuación, te explico los conceptos clave:
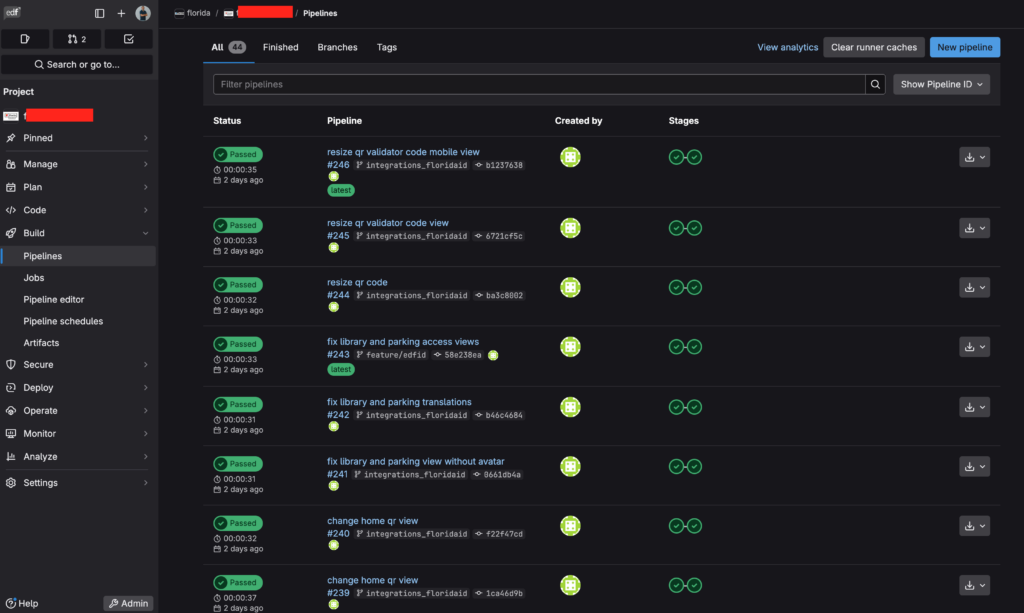
Listado de pipelines ejecutadas
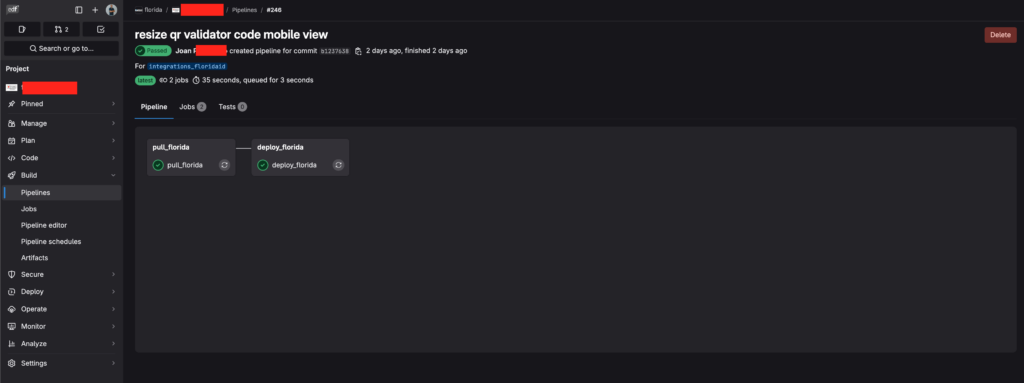
Trabajos de la pipeline
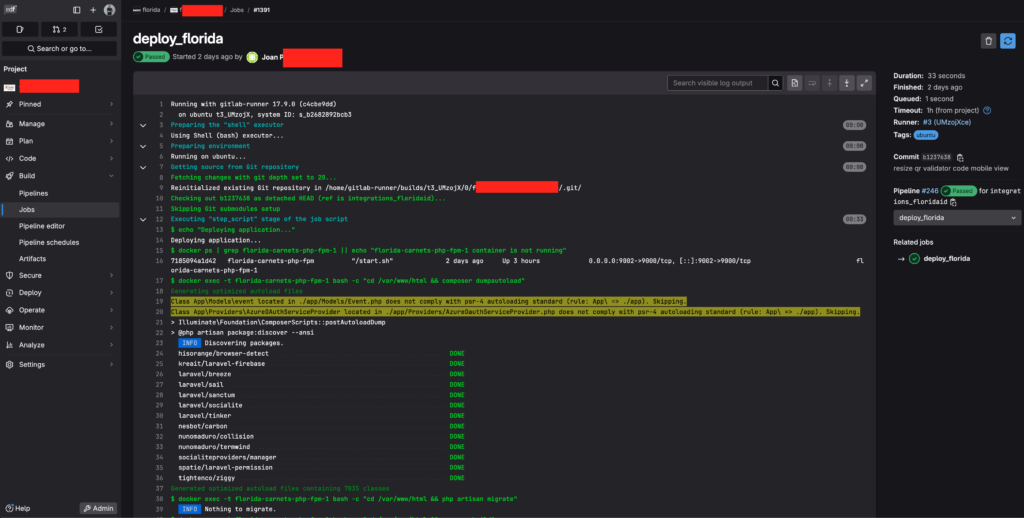
Salida de ejecución de un Job
1. Activación de pipelines
Las pipelines se ejecutan automáticamente en los siguientes casos:
- Trigger manual: Algunas pipelines pueden configurarse para ejecutarse manualmente, lo que es útil para despliegues en producción que requieren aprobación.
- Push a una rama: Cuando haces un push a una rama en tu repositorio, GitLab ejecuta automáticamente la pipeline asociada a esa rama.
- Merge Request (MR): Cuando creas o actualizas un Merge Request, GitLab puede ejecutar una pipeline para verificar que los cambios no rompan el código.
- Programación (Schedules): Puedes configurar pipelines para que se ejecuten en horarios específicos, como cada noche o los fines de semana.
2. Condiciones para ejcutar jobs
Cada job en una pipeline puede tener reglas específicas que determinan cuándo se ejecuta. Estas reglas se definen con las siguientes directivas:only y except
only: Especifica cuándo un job debe ejecutarse. Por ejemplo, puedes limitar un job a una rama específica:
deploy_production:
stage: deploy
script:
- echo "Desplegando en producción..."
only:
- maintest:
stage: test
script:
- echo "Ejecutando pruebas..."
except:
- developmentrules
La directiva rules es más flexible y permite definir condiciones complejas para la ejecución de jobs. Por ejemplo:
deploy_staging:
stage: deploy
script:
- echo "Desplegando en staging..."
rules:
- if: '$CI_COMMIT_BRANCH == "staging"'
when: always
- if: '$CI_COMMIT_BRANCH == "main"'
when: manualwhen
La directiva when define cuándo se ejecuta un job en relación con otros jobs. Los valores comunes son:
on_success: El job se ejecuta solo si todos los jobs anteriores en la misma etapa han tenido éxito (valor predeterminado).on_failure: El job se ejecuta solo si algún job anterior ha fallado.always: El job se ejecuta siempre, independientemente del resultado de los jobs anteriores.manual: El job debe activarse manualmente desde la interfaz de GitLab.
Ejemplo:
notify_failure:
stage: notify
script:
- echo "Algo salió mal. Notificando al equipo..."
when: on_failureConclusión: Por qué la automatización de despliegues con GitLab CI/CD es esencial para equipos de desarrollo
La implementación de CI/CD no es solo una herramienta técnica, sino un cambio cultural que transforma la forma en que los equipos de desarrollo abordan la entrega de software. A través de nuestra experiencia, aprendimos que los despliegues manuales no solo son propensos a errores, sino que también generan cuellos de botella que ralentizan la productividad y aumentan el estrés del equipo. La adopción de GitLab CI/CD nos permitió automatizar procesos, reducir riesgos y mejorar la colaboración, lo que resultó en un flujo de trabajo más eficiente y confiable.
Sin embargo, la implementación de CI/CD no está exenta de desafíos. Es crucial definir pipelines claros y separados para cada entorno (pre, staging y producción), así como implementar pruebas automatizadas que garanticen la calidad del código antes de su despliegue. Además, el uso de variables de entorno y la protección de información sensible son aspectos clave para mantener la seguridad y la integridad del proceso.
Otro punto importante es la flexibilidad que ofrece GitLab CI/CD mediante reglas como only, except, rules y when. Estas permiten adaptar el comportamiento de las pipelines a las necesidades específicas del proyecto, ya sea ejecutando jobs automáticamente en ciertas ramas, requiriendo aprobación manual para despliegues críticos o notificando al equipo en caso de fallos.
En resumen, CI/CD no solo acelera la entrega de software, sino que también mejora la calidad y fomenta la colaboración dentro del equipo. Para aquellos que aún no han dado el salto a la automatización, les recomendamos comenzar con un pipeline básico y escalar gradualmente, incorporando mejores prácticas como pruebas unitarias, pipelines multi-entorno y gestión segura de credenciales.
La historia de nuestro equipo es un testimonio de cómo CI/CD puede transformar un flujo de trabajo caótico en uno eficiente y confiable. Si estás enfrentando problemas similares, te animamos a explorar herramientas como GitLab CI/CD y a adoptar un enfoque más automatizado y colaborativo en tu desarrollo de software.
Reflexión final
La automatización no es solo una cuestión de tecnología, sino de cambio de mentalidad. Implica confiar en los procesos, en las pruebas automatizadas y en la capacidad del equipo para trabajar de manera coordinada. Al implementar CI/CD, no solo estás optimizando tu flujo de trabajo, sino también invirtiendo en la escalabilidad y sostenibilidad de tu proyecto a largo plazo.
Si tienes alguna pregunta, necesitas más detalles o quieres compartir tu propia experiencia con CI/CD, ¡no dudes en dejar un comentario! Estoy seguro de que muchos desarrolladores se beneficiarán de tu historia. 😊




