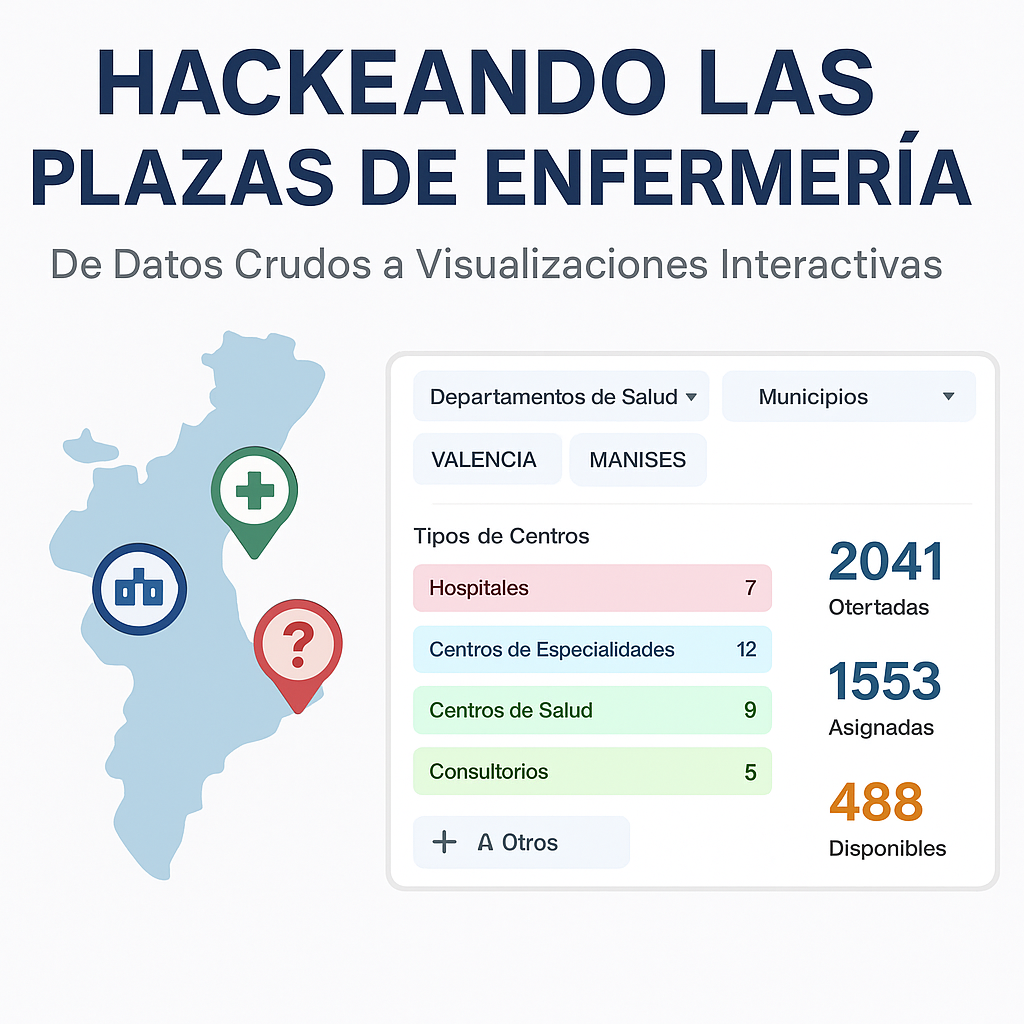
📋 Introducción: Visualizando la adjudicación de plazas de enfermería en la Comunitat Valenciana
En la primera parte de esta serie, publicada en Hackeando las Plazas de Enfermería en la Comunitat Valenciana (Parte 1), abordé el desafío de convertir un PDF caótico, lleno de datos desestructurados, en un dataset limpio y listo para usar. Esta segunda parte se centra en cómo transformar esos datos en visualizaciones interactivas que permiten a los usuarios explorar y analizar plazas de enfermería de forma más intuitiva y en tiempo real.
El objetivo de este proyecto es claro: democratizar el acceso a datos públicos, permitiendo que incluso aquellos sin formación técnica puedan tomar decisiones informadas. En un contexto donde las administraciones públicas deberían facilitar el acceso a información precisa y actualizada, herramientas como esta resultan esenciales. Sin embargo, los datos públicos a menudo se presentan en formatos complicados, como PDFs no estructurados, que dificultan su análisis incluso para profesionales como data scientists o geógrafos.
Imagina a Laura, una enfermera que, tras años de esfuerzo, sacrificio y estudio, finalmente ha superado las pruebas de la OPE. Después de haber trabajado durante años en condiciones provisionales y de esperar pacientemente a que se inicie el complejo proceso de traslados, se encuentra ahora con un nuevo desafío. En apenas unos días debe tomar una decisión crucial para su futuro profesional: escoger una plaza entre cientos de opciones, sin contar con herramientas que le permitan calcular y revisar en profundidad las alternativas disponibles.
Esta situación es más común de lo que parece. El proceso de elección de plaza puede ser caótico y estresante, especialmente cuando la información se presenta de manera fragmentada o inaccesible. Esta fue precisamente la motivación para escribir esta segunda parte del proyecto: crear una herramienta que facilite esta toma de decisiones, permitiendo a enfermeras como Laura explorar visualmente las plazas disponibles, filtrar resultados por departamento, municipio o tipo de centro sanitario, y exportar los datos para un análisis más profundo, sin tener que lidiar con documentos complejos o software técnico.
Además, el visor está diseñado para ser completamente accesible desde dispositivos móviles, permitiendo a los profesionales sanitarios consultar la información que necesitan cuando más lo requieren, sin importar dónde se encuentren. Esto hace que el proyecto sea especialmente relevante para quienes trabajan en un sector tan dinámico y crítico como la sanidad.
En los siguientes apartados, detallaré cómo se realizó esta transformación, desde la extracción de datos hasta la creación del visor interactivo, pasando por la integración de tecnologías avanzadas como Vue.js, Leaflet y PrimeVue, que hacen posible esta experiencia de usuario fluida y enriquecedora.
TABLA DE CONTENIDOS
Extracción de Datos desde el PDF
La Generalitat Valenciana ha publicado recientemente un documento titulado «DILIGENCIA por la que se hace constar que en la fecha de la firma, se publica en la página web de la Conselleria de Sanidad (www.san.gva.es) la RESOLUCIÓN de 7 de mayo de 2025, de la Dirección General de Personal, por la que se publica la adjudicación de plazas de los siguientes procesos selectivos para la provisión de vacantes de enfermera o enfermero de instituciones sanitarias de la Conselleria de Sanidad: por concurso-oposición, derivado de las ofertas de empleo público de los años 2017, 2018 y por estabilización de 2019; y por concurso de méritos excepcional de estabilización, derivado de la oferta de empleo público del año 2022″.
Este documento contiene una serie de tablas con datos que necesitamos extraer para poder procesar la información de manera eficiente. Sin embargo, como suele ser el caso con este tipo de publicaciones, los datos se presentan de forma no estructurada, lo que dificulta su uso directo en aplicaciones interactivas como nuestro visor de plazas de enfermería.
Extrayendo los datos de la adjudicación con Python
Una vez publicada esta resolución, nos encontramos ante un nuevo reto técnico: conectar la información de adjudicación recientemente publicada con nuestros datos geográficos iniciales. Esto requiere una combinación precisa de análisis de datos y habilidades técnicas para transformar este PDF en un formato estructurado y utilizable.
En la primera fase del proyecto, logramos generar un archivo GeoJSON con información geográfica detallada sobre cada centro sanitario, incluyendo nombre, dirección, coordenadas y tipo de centro. Ahora, para que nuestro visor sea realmente útil, necesitamos combinar esta información geográfica con los datos de adjudicación. Esto no solo implica cargar un archivo GeoJSON con ubicaciones, sino también extraer, limpiar y agrupar datos desde un PDF complejo.
Imagina a David, un desarrollador de datos que quiere convertir este caos en un formato utilizable para nuestra aplicación. Él sabe que solo necesita unos pocos campos clave para que el visor cobre vida:
- Código del centro
- Nombre del centro sanitario
- Departamento sanitario
- Municipio
- Número total de plazas adjudicadas
Con estos elementos en mente, escribí un script en Python para extraer los datos, transformarlos en un formato estructurado y, finalmente, combinarlos con nuestras capas geográficas para generar una visualización precisa y útil para los profesionales sanitarios.
A continuación, detallo cómo se realizó este proceso, desde la extracción inicial hasta la integración final en nuestro visor interactivo.
Paso 1: Cargar el PDF y extraer tablas
El primer paso para transformar los datos de adjudicación en un formato utilizable es cargar el archivo PDFproporcionado por la Generalitat Valenciana y extraer las tablas que contienen la información que necesitamos. Para esto, utilizaremos pdfplumber, una librería en Python diseñada específicamente para manejar documentos PDF complejos.
El documento oficial publicado por la Conselleria de Sanidad incluye múltiples tablas distribuidas en casi 100 páginas, comenzando en la página 4 y terminando en la 102. Estos datos son fundamentales para nuestro visor, ya que contienen detalles como el código del centro, el nombre del centro sanitario, el departamento, el municipio y el número total de plazas adjudicadas.
Para cargar el PDF y extraer las tablas, usaremos el siguiente script en Python:
import pdfplumber
import pandas as pd
from pathlib import Path
def extract_tables_from_pdf(pdf_path: Path, page_start: int = 4, page_end: int = 102) -> pd.DataFrame:
"""
Extrae las tablas de un archivo PDF entre las páginas especificadas y las combina en un solo DataFrame.
"""
tables = []
with pdfplumber.open(pdf_path) as pdf:
for page_number in range(page_start, page_end + 1):
print(f"Procesando página {page_number}...")
page = pdf.pages[page_number - 1]
table = page.extract_table()
if table:
df = pd.DataFrame(table[1:], columns=table[0])
tables.append(df)
# Combinar todas las tablas extraídas en un solo DataFrame
if tables:
combined_df = pd.concat(tables, ignore_index=True)
print(f"Se han extraído {len(combined_df)} filas de datos.")
return combined_df
else:
print("No se encontraron tablas en el rango de páginas especificado.")
return pd.DataFrame()
# Ruta al archivo PDF
pdf_file_path = Path("resolucion_adjudicacion_ope.pdf")
# Extraer las tablas
data_df = extract_tables_from_pdf(pdf_file_path)
# Mostrar las primeras filas para verificar los datos extraídos
print(data_df.head())
Qué hace este script:
- Carga el PDF usando
pdfplumber.open()para acceder a las páginas del documento. - Itera sobre cada página en el rango especificado (páginas 4 a 102).
- Extrae las tablas de cada página usando
extract_table(), ignorando filas vacías y manteniendo los encabezados de las tablas. - Combina todas las tablas en un único
DataFramede Pandas para facilitar el procesamiento posterior. - Muestra las primeras filas del
DataFramepara verificar que los datos se hayan extraído correctamente.
Después de unos segundos trabajando, el script nos muestra que ha extraído un DataFrame de Pandas de 5382 filas por 10 columnas.

En el siguiente paso, nos enfocaremos en limpiar y transformar estos datos para hacerlos compatibles con nuestro visor interactivo.
Paso 2: Unificar tablas y limpiar los datos
Después de extraer las tablas, es fundamental unificarlas en un único DataFrame para facilitar el análisis. Además, debemos normalizar los nombres de las columnas para eliminar saltos de línea y espacios adicionales que pueden causar errores más adelante.
# Unimos todas las tablas en un único DataFrame
combined_df = pd.concat(tables, ignore_index=True)
# Normalizamos los nombres de columnas eliminando saltos de línea y espacios adicionales
combined_df.columns = (
combined_df.columns
.str.replace('\n', ' ', regex=False) # Reemplaza saltos de línea por espacios
.str.replace(r'\s+', ' ', regex=True) # Elimina espacios múltiples
.str.strip() # Elimina espacios al inicio y al final
)📍 Paso 3: Filtrar columnas necesarias
El PDF puede contener muchas columnas irrelevantes o datos personales que no necesitamos para nuestro visor. Por eso, es importante filtrar solo las columnas esenciales:
# Columnas necesarias para nuestro análisis
required_columns = ['Codi centre', 'Centre', 'Departament', 'Municipi']
# Verificamos que todas las columnas necesarias existan en el DataFrame
missing_columns = set(required_columns) - set(combined_df.columns)
if missing_columns:
raise KeyError(f"⚠️ Faltan columnas esenciales: {missing_columns}")
# Filtramos el DataFrame para mantener solo columnas relevantes
filtered_df = combined_df[required_columns]📊 Paso 4: Agrupar y contar las plazas adjudicadas por centro
Finalmente, agrupamos los datos para contar el total de plazas adjudicadas por cada centro sanitario. Esto es esencial para que nuestro visor pueda mostrar de forma precisa la cantidad de plazas disponibles por ubicación:
# Agrupamos por centro, departamento y municipio y contamos las plazas adjudicadas
summary_df = (
filtered_df
.groupby(['Codi centre', 'Centre', 'Departament', 'Municipi'], as_index=False)
.size()
.rename(columns={'size': 'Total plazas'})
.sort_values(['Total plazas', 'Codi centre'], ascending=[False, True])
)Puntos a tener en cuenta:
- Validación de columnas: Si alguna de las columnas requeridas no está presente, el script lanzará una excepción (
KeyError), evitando errores en etapas posteriores. - Ordenación inteligente: Se ordenan los resultados primero por total de plazas (de mayor a menor) y luego por código de centro (de menor a mayor) para facilitar la navegación en el visor.
- Eliminación de duplicados: Agrupar los datos ayuda a consolidar las plazas duplicadas, evitando errores en los conteos.
Paso 5: Guardar los resultados en CSV
Por último, exportamos nuestro resumen a un archivo CSV, que podremos integrar fácilmente en nuestra visualización interactiva:
output_csv = Path("resumen_plazas_por_centro.csv")
summary_df.to_csv(output_csv, index=False)
print(f"✅ CSV generado correctamente en: {output_csv}")
Paso 6: Juntado todos los pasos en un sólo script
import pdfplumber
import pandas as pd
from pathlib import Path
def extract_and_process_tables(pdf_path: Path, page_start: int = 4, page_end: int = 102) -> pd.DataFrame:
"""
Extrae tablas de un PDF, limpia los datos y agrupa las plazas adjudicadas por centro sanitario.
"""
# 🗂️ Paso 1: Cargar el PDF y extraer tablas
tables = []
with pdfplumber.open(pdf_path) as pdf:
for page_number in range(page_start, page_end + 1):
print(f"📄 Procesando página {page_number}...")
page = pdf.pages[page_number - 1]
table = page.extract_table()
if table:
df = pd.DataFrame(table[1:], columns=table[0])
tables.append(df)
if not tables:
print("⚠️ No se encontraron tablas en el rango de páginas especificado.")
return pd.DataFrame()
# 🧹 Paso 2: Unificar tablas y limpiar los datos
combined_df = pd.concat(tables, ignore_index=True)
# Normalizamos los nombres de columnas eliminando saltos de línea y espacios adicionales
combined_df.columns = (
combined_df.columns
.str.replace('\n', ' ', regex=False) # Reemplaza saltos de línea por espacios
.str.replace(r'\s+', ' ', regex=True) # Elimina espacios múltiples
.str.strip() # Elimina espacios al inicio y al final
)
print("🧹 Nombres de columnas normalizados:")
print(combined_df.columns)
# 📍 Paso 3: Filtrar columnas necesarias
required_columns = ['Codi centre', 'Centre', 'Departament', 'Municipi']
missing_columns = set(required_columns) - set(combined_df.columns)
if missing_columns:
raise KeyError(f"⚠️ Faltan columnas esenciales: {missing_columns}")
filtered_df = combined_df[required_columns]
# 📊 Paso 4: Agrupar y contar las plazas adjudicadas por centro
summary_df = (
filtered_df
.groupby(['Codi centre', 'Centre', 'Departament', 'Municipi'], as_index=False)
.size()
.rename(columns={'size': 'Total plazas'})
.sort_values(['Total plazas', 'Codi centre'], ascending=[False, True])
)
print(f"✅ Se han agrupado {len(summary_df)} registros únicos de centros sanitarios.")
return summary_df
# 🗂️ Ruta al archivo PDF
pdf_file_path = Path("resolucion_adjudicacion_ope.pdf")
# 📝 Extraer, limpiar y agrupar los datos
processed_df = extract_and_process_tables(pdf_file_path)
# 🖥️ Mostrar las primeras filas para verificar el resultado
print(processed_df.head())
# 💾 Guardar el resultado en un archivo CSV para análisis posterior
output_csv_path = Path("plazas_adjudicadas.csv")
processed_df.to_csv(output_csv_path, index=False, encoding="utf-8")
print(f"💾 Datos exportados correctamente a {output_csv_path}")
El resultado es un DataFrame claro y estructurado, listo para integrarse en nuestra aplicación:

Características del Script:
- Extracción de Tablas: Lee las tablas del PDF usando
pdfplumberdesde las páginas 4 a 102. - Normalización de Columnas: Elimina saltos de línea y espacios innecesarios en los nombres de columnas.
- Filtrado de Columnas: Retiene solo las columnas relevantes (
Codi centre,Centre,Departament,Municipi). - Agrupación de Datos: Cuenta el total de plazas adjudicadas por centro y las ordena por cantidad de plazas y código de centro.
- Exportación a CSV: Guarda el resultado en un archivo
plazas_adjudicadas.csvpara uso posterior.
Próximos Pasos:
- Verificación y limpieza adicional para manejar casos de nombres duplicados o inconsistencias en los datos.
- Conversión a GeoJSON para integrar los datos en tu visor interactivo de plazas.
Fusión de Datos entre el DataSet de Centros Sanitarios y las Plazas Extraídas del PDF
Una vez que hemos limpiado y estructurado los datos de los centros sanitarios en el archivo centres.csv, el siguiente paso es enriquecer esta información con los datos de plazas adjudicadas que hemos extraído del PDF de la Generalitat y de las plazas ofrecidas que extrajimos de la primera parte del artículo. Esta fusión es crucial para poder visualizar no solo la ubicación de cada centro, sino también las oportunidades laborales disponibles para los profesionales de enfermería.
Te dejo aquí los DataSet centres.csv y plazas.csv generados y extraídos en el artículo anterior, el fichero adjudicadas.csv resultado del primer paso de este artículo así como el fichero PDF del que extraje las plazas ofrecidas.
Paso 1: Generación del DataSet plazas_por_centro.csv
En este primer paso, vamos a combinar los datos de plazas ofrecidas (extraídos en la primera parte del artículo y que tienes en el DataSet plazas.csv) con los datos de plazas adjudicadas (extraídos en esta segunda parte) y calcular las diferencias entre ambos. El objetivo es crear un archivo plazas_por_centro.csv que consolidará esta información para su uso en el visor interactivo.
Columnas Esperadas:
El script espera que los archivos de entrada tengan las siguientes columnas:
- Plazas ofrecidas (
plazas.csv):asi– Área Sanitaria Integradadepartamento– Departamento de SaludCodi centre– Código único del centrocentro– Nombre del centromunicipio– Municipio del centronumero– Número total de plazas ofrecidas
- Plazas adjudicadas (
adjudicadas.csv):Codi centre– Código único del centroCentre– Nombre del centroDepartament– Departamento de SaludMunicipi– Municipio del centroTotal plazas– Número total de plazas adjudicadas
A continuación te pongo el código del Script de Python que he utilizado para generar el DataSet resultante plazas_por_centro.csv .
import pandas as pd
from pathlib import Path
def generar_dataset_plazas(ofrecidas_csv: Path, adjudicadas_csv: Path, output_csv: Path):
"""
Combina las plazas ofrecidas (ya extraídas en la primera parte del artículo)
con las plazas adjudicadas (extraídas en este artículo) y calcula la diferencia entre ambas.
Genera un archivo CSV con las siguientes columnas:
- Codi centre: Código único del centro sanitario
- asi: Área Sanitaria Integrada
- departamento: Departamento de Salud
- centro: Nombre del centro
- municipio: Municipio del centro
- Plazas_ofrecides: Número total de plazas ofrecidas
- Total plazas: Número total de plazas adjudicadas
- Diferencia: Plazas_ofrecides - Total plazas
El archivo de salida se ordena de mayor a menor según 'Plazas_ofrecides'.
"""
# 📥 Leer plazas ofrecidas desde CSV
print(f"📥 Leyendo plazas ofrecidas desde: {ofrecidas_csv}")
df_of = pd.read_csv(ofrecidas_csv, dtype=str)
# Validar que el CSV tenga las columnas correctas
required_columns = {'asi', 'departamento', 'Codi centre', 'centro', 'municipio', 'numero'}
missing_columns = required_columns - set(df_of.columns)
if missing_columns:
raise KeyError(f"⚠️ Faltan columnas en el CSV de ofertas: {missing_columns}")
# 🧹 Limpiar códigos de centro y convertir plazas a enteros
print("🧹 Normalizando datos de plazas ofrecidas...")
df_of['Codi centre'] = pd.to_numeric(df_of['Codi centre'].str.strip(), errors='coerce').fillna(0).astype(int)
df_of['numero'] = pd.to_numeric(df_of['numero'].str.replace(r'[^\d\-]', '', regex=True), errors='coerce').fillna(0).astype(int)
df_of.rename(columns={"numero": "Plazas_ofrecides"}, inplace=True)
# 📥 Leer plazas adjudicadas desde CSV
print(f"📥 Leyendo plazas adjudicadas desde: {adjudicadas_csv}")
df_ad = pd.read_csv(adjudicadas_csv, dtype=str)
required = {'Codi centre', 'Centre', 'Departament', 'Municipi', 'Total plazas'}
missing = required - set(df_ad.columns)
if missing:
raise KeyError(f"⚠️ Faltan columnas en adjudicadas: {missing}")
# 🧹 Limpiar códigos de centro y convertir plazas a enteros
print("🧹 Normalizando datos de plazas adjudicadas...")
df_ad['Codi centre'] = pd.to_numeric(df_ad['Codi centre'].str.strip(), errors='coerce').fillna(0).astype(int)
df_ad['Total plazas'] = pd.to_numeric(df_ad['Total plazas'].str.replace(r'[^\d\-]', '', regex=True), errors='coerce').fillna(0).astype(int)
# 🔗 Unir ambos datasets en base al código de centro
print("🔗 Combinando datasets...")
df = pd.merge(
df_of[['Codi centre', 'asi', 'departamento', 'centro', 'municipio', 'Plazas_ofrecides']],
df_ad[['Codi centre', 'Centre', 'Departament', 'Municipi', 'Total plazas']],
on='Codi centre',
how='left'
).fillna({'Total plazas': 0, 'Centre': '', 'Departament': '', 'Municipi': ''})
# ➖ Calcular diferencia de plazas
print("➖ Calculando diferencias...")
df['Diferencia'] = df['Plazas_ofrecides'] - df['Total plazas']
# 🧹 Convertir todos los números a enteros
df['Codi centre'] = df['Codi centre'].astype(int)
df['Plazas_ofrecides'] = df['Plazas_ofrecides'].astype(int)
df['Total plazas'] = df['Total plazas'].astype(int)
df['Diferencia'] = df['Diferencia'].astype(int)
# 📋 Reordenar columnas para mayor claridad
df = df[
['Codi centre', 'asi', 'departamento', 'centro', 'municipio', 'Plazas_ofrecides', 'Total plazas', 'Diferencia']
]
# 📊 Ordenar de mayor a menor según 'Plazas_ofrecides'
print("📊 Ordenando dataset final...")
df.sort_values('Plazas_ofrecides', ascending=False, inplace=True)
# 💾 Guardar a CSV
print(f"💾 Guardando dataset final en: {output_csv}")
df.to_csv(output_csv, index=False, encoding="utf-8")
print(f"✅ CSV generado y ordenado en: {output_csv}")
if __name__ == "__main__":
# 📁 Rutas de los archivos
plazas_csv = Path("plazas.csv")
adjudicadas_csv = Path("adjudicadas.csv")
salida_csv = Path("plazas_por_centro.csv")
# 📝 Generar dataset comparativo en CSV
generar_dataset_plazas(plazas_csv, adjudicadas_csv, salida_csv)
Resultado Esperado (plazas_por_centro.csv te dejo aquí su contenido):

Paso 2: Generación del Archivo centres.geojson
En este segundo paso, vamos a combinar el archivo plazas_por_centro.csv (generado en el paso anterior) con el archivo centres.csv, que contiene las coordenadas geográficas y la información estructural de cada centro sanitario. El objetivo es crear un archivo centres.geojson que pueda ser utilizado directamente en el visor interactivo de plazas.
Columnas Esperadas:
El script espera que los archivos de entrada tengan las siguientes columnas:
- Centros sanitarios (
centres.csv):cen_cod– Código único del centro sanitariocen_codpos– Código postal del centrocen_desclar– Nombre del centrocen_nombcall– Nombre de la callecen_numcall– Número de la callecod_ine_mun– Código INE del municipiocodigo_departamento– Código del departamento de saludlat– Latitud del centrolon– Longitud del centromunicipio– Nombre del municipionombre_departamento– Nombre del departamento de saludprovincia– Provincia del centrotipo– Tipo de centro sanitario
- Plazas por centro (
plazas_por_centro.csv):Codi centre– Código único del centroPlazas_ofrecides– Número total de plazas ofrecidasTotal plazas– Número total de plazas adjudicadas
Código del script:
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
from pathlib import Path
def generar_centres_geojson(centres_csv: Path, plazas_csv: Path, output_file: Path):
"""
Genera un archivo GeoJSON combinando datos de centros sanitarios y plazas adjudicadas.
"""
# Mapeo de nombres de columnas para consistencia
column_mapping = {
"cen_cod": "center_id",
"cen_codpos": "postal_code",
"cen_desclar": "center_name",
"cen_nombcall": "street_name",
"cen_numcall": "street_number",
"cod_ine_mun": "municipality_code",
"codigo_departamento": "department_code",
"lat": "latitude",
"lon": "longitude",
"municipio": "municipality",
"nombre_departamento": "department_name",
"provincia": "province",
"tipo": "center_type"
}
try:
# 📥 Cargar datos de centros sanitarios
print(f"📥 Cargando datos desde: {centres_csv}")
df_centres = pd.read_csv(centres_csv)
# Renombrar columnas para consistencia
df_centres.rename(columns=column_mapping, inplace=True)
# 📥 Cargar datos de plazas adjudicadas
print(f"📥 Cargando datos desde: {plazas_csv}")
df_vacancies = pd.read_csv(plazas_csv, usecols=["Codi centre", "Plazas_ofrecides", "Total plazas"])
# Realizar el merge (left join) usando el código de centro como clave
print("🔗 Combinando datos de centros y plazas...")
df_merged = pd.merge(df_centres, df_vacancies, how="left", left_on="center_id", right_on="Codi centre")
# Renombrar las columnas de plazas para mayor claridad
df_merged.rename(columns={
"Plazas_ofrecides": "vacancies_offered",
"Total plazas": "vacancies_assigned"
}, inplace=True)
# Reemplazar NaN por 0 en plazas ofrecidas y asignadas
df_merged["vacancies_offered"] = df_merged["vacancies_offered"].fillna(0).astype(int)
df_merged["vacancies_assigned"] = df_merged["vacancies_assigned"].fillna(0).astype(int)
# Calcular la diferencia entre plazas ofrecidas y asignadas
print("➖ Calculando diferencias...")
df_merged["vacancies_difference"] = df_merged["vacancies_offered"] - df_merged["vacancies_assigned"]
# Crear geometría a partir de lon/lat
print("🌍 Generando geometrías...")
df_merged["geometry"] = df_merged.apply(lambda row: Point(float(row["longitude"]), float(row["latitude"])), axis=1)
# Crear GeoDataFrame
gdf = gpd.GeoDataFrame(df_merged, geometry="geometry", crs="EPSG:4326")
# Eliminar columnas redundantes
gdf.drop(columns=["Codi centre"], inplace=True)
# Exportar a GeoJSON
print(f"💾 Guardando archivo GeoJSON en: {output_file}")
gdf.to_file(output_file, driver="GeoJSON", encoding="utf-8")
print(f"✅ GeoJSON generado correctamente: {output_file}")
except FileNotFoundError as e:
print(f"❌ Archivo no encontrado: {e.filename}")
except pd.errors.EmptyDataError:
print(f"❌ El archivo CSV está vacío.")
except Exception as e:
print(f"⚠️ Error inesperado: {e}")
if __name__ == "__main__":
# 📁 Rutas de los archivos
centres_csv = Path("centres.csv")
plazas_csv = Path("plazas_por_centro.csv")
output_file = Path("centres.geojson")
# 📝 Generar archivo GeoJSON
generar_centres_geojson(centres_csv, plazas_csv, output_file)
Resultado Esperado (centres.geojson):
El archivo centres.geojson – te lo dejo aquí – generado tendrá una estructura similar a:

Para comprobar que todo está bien y los datos se han generado correctamente, podemos utilizar un servicio para validar y visualizar el fichero GeoJSON como GeoJSON.io al que le podemos pegar el fichero resultado de este paso y navegar por el mapa, visualizando los diferentes centros sanitarios y revisando la información generada.
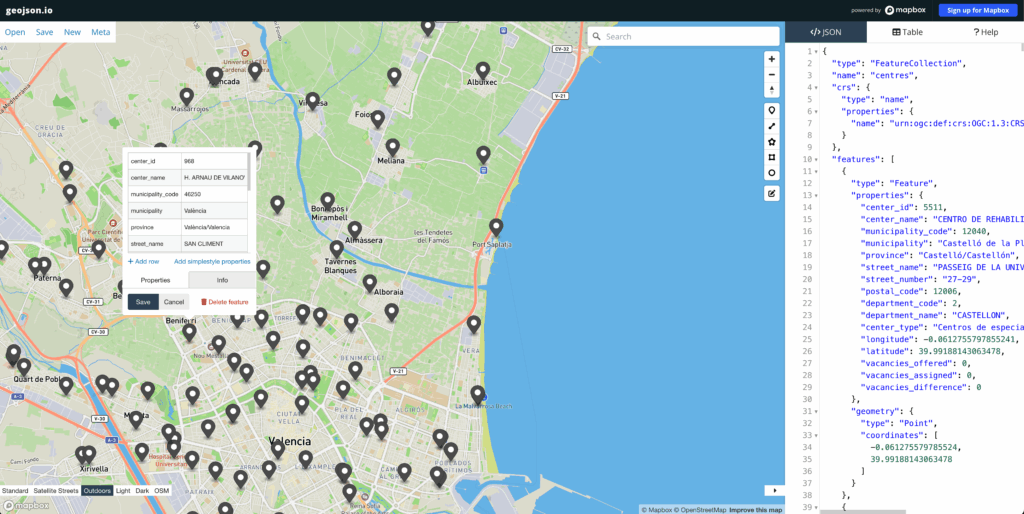
Una vez extraídos los centros sanitarios junto a sus datos geográficos, tipológicos y de número de plazas, podemos proceder al desarrollo del visor interactivo.
El Visor Interactivo: Tecnologías y Enfoque de Desarrollo
Ahora que hemos generado el archivo centres.geojson, es momento de integrarlo en un visor interactivo que permita explorar las plazas sanitarias de forma intuitiva y en tiempo real. Este visor, alojado en GitHub Pages, está diseñado para ser rápido, escalable y fácil de mantener, utilizando un stack moderno que prioriza el rendimiento y la modularidad.
👉 Visor de Plazas de Enfermería GVA
Tecnologías Utilizadas
- Leaflet: Biblioteca ligera para visualización de datos geoespaciales. Facilita la integración de mapas interactivos, agrupación de marcadores y overlays personalizados. Ideal para aplicaciones geográficas con grandes volúmenes de datos.
- Vue.js 3: El corazón de la aplicación. Utilizado para la lógica del frontend, manejo del estado y renderizado reactivo de componentes. Ofrece un desarrollo más estructurado y modular, perfecto para aplicaciones SPA (Single Page Application).
- Tailwind CSS 4: Framework utility-first que permite crear interfaces rápidas, consistentes y responsivas con un enfoque mobile-first, ideal para aplicaciones de alto rendimiento.
- PrimeVue 4: Biblioteca de componentes avanzados para Vue.js que incluye elementos como paneles, tablas, botones y formularios, acelerando el desarrollo sin sacrificar calidad visual.
Estas tecnologías permiten que el visor sea rápido, ligero y escalable, con un enfoque mobile-first que garantiza una experiencia fluida en dispositivos móviles.
🤖 Uso de IA con GitHub Copilot
Para acelerar el desarrollo y mejorar la calidad del código, se utilizó GitHub Copilot, una herramienta de inteligencia artificial que asiste en la escritura de código. Esta IA fue especialmente útil en varias áreas del proyecto, incluyendo:
- Generación Rápida de Código: Ayudó a crear rápidamente los esqueletos de componentes como
MapView.vue,FiltersDrawer.vueyFloatingStatsPanel.vue, sugiriendo estructuras de datos y patrones de diseño óptimos. - Optimización de Lógica de Negocio: Facilitó la creación de composables como
usePlazas.js, mejorando la organización del código y minimizando errores lógicos al manejar datos complejos de plazas. - Reducción de Errores Tipográficos: Copilot sugirió correcciones para errores comunes, como nombres de variables inconsistentes y problemas de indentación, mejorando la calidad del código.
- Ahorro de Tiempo en Documentación: Generó descripciones detalladas de funciones y bloques de código, lo que facilitó la documentación del proyecto.
- Optimización del Código CSS: Ayudó a escribir utilidades personalizadas para Tailwind CSS, como clases para colores dinámicos y estilos responsivos.
Características del Visor:
- Experiencia Fluida en Móviles: Diseño optimizado para dispositivos móviles, con tiempos de carga rápidos y transiciones suaves.
- Modularidad y Escalabilidad: Uso de componentes reutilizables y lógica encapsulada en composables para facilitar futuras ampliaciones.
- Visualización Geoespacial Avanzada: Puntos interactivos con colores dinámicos según disponibilidad de plazas, agrupación automática y pop-ups informativos.
- Filtros Dinámicos: Filtros avanzados para explorar datos según tipo de centro, municipio y número de plazas.
- Despliegue Continuo: Aprovecha GitHub Pages para despliegues rápidos y sin costo, con alta disponibilidad y versionado automático.
Estructura del Proyecto
El visor de plazas de enfermería ha sido diseñado para ser modular, escalable y fácil de mantener, aprovechando las mejores prácticas del desarrollo moderno en Vue.js 3, Leaflet y Tailwind CSS 4. La estructura del proyecto sigue un enfoque component-first, donde cada parte de la aplicación (mapa, filtros, estadísticas) se organiza en módulos independientes para facilitar el mantenimiento y futuras ampliaciones. Además, se han incluido composables para encapsular la lógica de negocio, garantizando que los datos y la lógica de presentación estén bien separados, lo que mejora la legibilidad y reutilización del código.
Esta es la estructura de ficheros y directorios:
project-root/
│
├── index.html # Punto de entrada de la aplicación
├── package.json # Dependencias y scripts del proyecto
├── postcss.config.cjs # Configuración de PostCSS para Tailwind CSS
│
├── public/
│ ├── centres.geojson # Datos geográficos de los centros sanitarios
│ ├── logo.png # Logo de la aplicación
│ ├── manifest.json # Configuración para PWA (Progressive Web App)
│ └── icons/ # Iconos para dispositivos y PWA
│ ├── apple-touch-icon.png
│ ├── favicon.ico
│ ├── icon-144×144.png
│ ├── icon-192-maskable.png
│ ├── icon-192.png
│ ├── icon-512-maskable.png
│ └── icon-512.png
│
├── src/
│ ├── App.vue # Componente raíz de la aplicación
│ ├── main.js # Punto de entrada de la aplicación Vue
│ ├── registerServiceWorker.js # Registro del Service Worker para PWA
│ ├── styles.css # Estilos globales
│ │
│ ├── components/ # Componentes reutilizables
│ │ ├── FiltersDrawer.vue # Filtros avanzados
│ │ ├── FloatingStatsPanel.vue # Panel de estadísticas flotante
│ │ ├── MapView.vue # Módulo principal del mapa
│ │ └── RawDataPanel.vue # Tabla de datos sin mapas
│ │
│ │
│ ├── composables/ # Lógica de negocio y hooks reutilizables
│ │ └── usePlazas.js # Manejo de datos de plazas sanitarias
│ │
│ └── i18n/ # Internacionalización
│ └── index.js # Configuración de idiomas
│
├── sw.js # Service Worker para cacheo y funcionalidad offline
├── tailwind.config.cjs # Configuración de Tailwind CSS
└── vite.config.js # Configuración de Vite para desarrollo y construcción
Ficheros de cada directorio
📁 public/
- centres.geojson: Archivo crítico que contiene los datos geográficos de los centros sanitarios.
- manifest.json: Configuración para convertir la aplicación en una PWA, permitiendo su instalación en dispositivos móviles.
- icons/:
- Incluye iconos para diferentes tamaños, necesarios para dispositivos iOS, Android y navegadores modernos.
- Los archivos maskable son importantes para mejorar la apariencia en dispositivos Android.
📁 src/components/
- FiltersDrawer.vue: Controla los filtros avanzados para refinar la visualización de datos.
- FloatingStatsPanel.vue: Muestra estadísticas en tiempo real sobre las plazas visibles.
- MapView.vue: El núcleo del visor, responsable de cargar y renderizar los datos geoespaciales.
- RawDataPanel.vue: Permite explorar los datos en formato tabular, ideal para análisis detallado.
📁 src/composables/
- usePlazas.js: Encapsula la lógica de negocio para el manejo de datos de plazas, incluyendo carga, filtrado y cálculo de métricas. Esto es una buena práctica que mejora la mantenibilidad del código.
📁 src/i18n/
- index.js: Configuración para soporte multilingüe. Esto es especialmente útil si planeas expandir la aplicación a otros idiomas.
📁 Archivos Raíz (src/)
- App.vue: Punto de entrada principal de la aplicación, que define la estructura básica y lógica global.
- main.js: Archivo de inicialización que monta la aplicación en el DOM.
- styles.css: Archivo de estilos globales, gestionado por Tailwind.
- registerServiceWorker.js: Permite que la aplicación funcione offline y cargue más rápido con un service worker.
📝 Configuración de Herramientas de Build
- tailwind.config.cjs: Configuración de Tailwind CSS, define colores personalizados y breakpoints.
- vite.config.js: Configuración de Vite para desarrollo y producción rápida. Vite es una excelente elección para este tipo de proyectos por su velocidad y simplicidad.
Flujo de Datos y Eventos en el Visor
El visor sigue un enfoque de datos unidireccional, donde los cambios en los filtros se propagan desde los componentes hacia los datos, manteniendo siempre sincronizada la interfaz. Esto simplifica el mantenimiento y mejora la predictibilidad del comportamiento de la aplicación.
- Carga de Datos:
usePlazas.jscarga los datos desdecentres.geojson, los normaliza y los expone como features para el mapa. Esto garantiza que los datos estén siempre actualizados y correctamente formateados. - Aplicación de Filtros:
FiltersDrawer.vueemite eventos cuando el usuario cambia los filtros, lo que desencadena el recalculo de datos visibles enusePlazas.js. Esto permite aplicar filtros sin necesidad de recargar toda la página. - Renderizado de Mapa:
MapView.vueescucha estos cambios y actualiza los marcadores en función de los datos filtrados, asegurando que solo se muestren los centros que cumplen con los criterios seleccionados. - Visualización de KPIs:
FloatingStatsPanel.vuemuestra métricas en tiempo real basadas en los datos actualmente visibles, proporcionando un resumen rápido del estado de las plazas. - Exportación de Datos:
RawDataPanel.vuepermite exportar los datos filtrados a CSV para análisis externo, mejorando la usabilidad para usuarios avanzados que requieren análisis más detallados.
🚀 Funcionalidades del Visor Interactivo
Para que esta herramienta sea verdaderamente útil, he desarrollado un conjunto de funcionalidades avanzadas:
Una vez que tenemos un DataSet con información precisa de los Centros Sanitarios, incluyendo correcciones en ubicaciones y datos, pasamos a desarrollar la aplicación de visualización. Este visor, que está alojado en GitHub Pages en https://andreums.github.io/visor_ope_enfermeria_gva_2022/, ha sido desarrollado utilizando las siguientes tecnologías:
- Tailwind CSS 4 para el diseño responsivo y estilización.
- PrimeVue 4 para componentes avanzados de interfaz.
- VueJS 3 para la lógica de la aplicación y gestión del estado.
- Leaflet para la visualización geoespacial y manejo de mapas interactivos.
El proyecto está alojado en GitHub Pages:
👉 https://andreums.github.io/visor_ope_enfermeria_gva_2022/
🚀 Funcionalidades del Visor Interactivo
El visor es mucho más que un simple mapa. Es una aplicación completa pensada para explorar, comparar y exportar información sobre plazas de enfermería, incluyendo:
- Visualización geoespacial con múltiples capas y clustering adaptativo.
- Filtros avanzados por área de salud, tipo de centro y municipio.
- Popups detallados con información completa sobre cada centro sanitario.
- Exportación a CSV para análisis externo.
- Generación de rutas por carretera desde un lugar o domicilio hasta el centro sanitario para hacerse una idea de la distancia a la que está situado el centro sanitario.
- Utilización de la geolocalización del dispositivo para obtener distancias hasta el centro sanitario seleccionado.
- Utilizar un dispositivo móvil para navegar por el mapa y consultar datos desde cualquier parte.
- Soporte PWA para carga rápida y navegación cómoda en dispositivo móvil.
En las siguientes secciones, detallo cómo cada una de estas funcionalidades se integra en la arquitectura del proyecto.
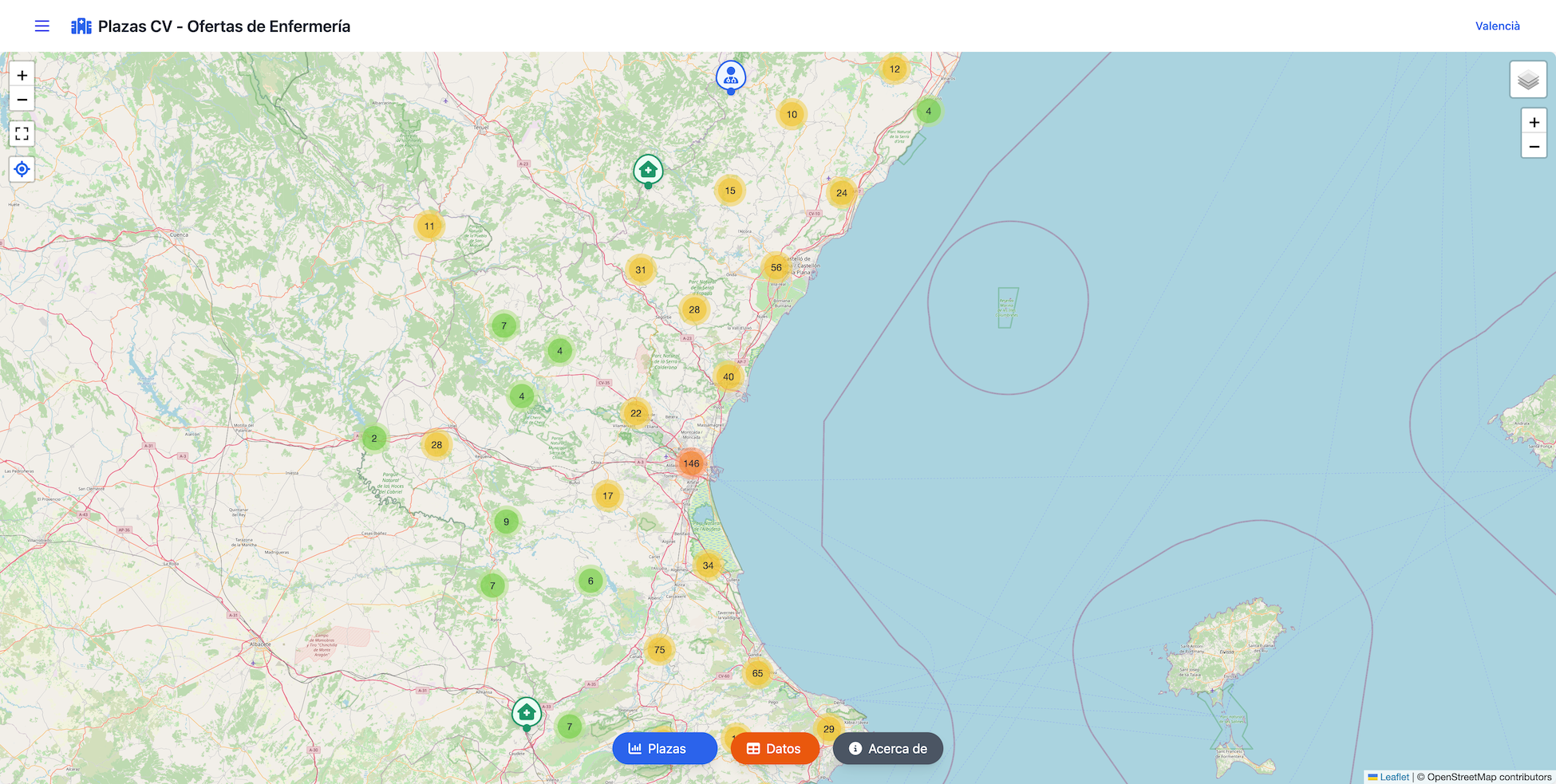
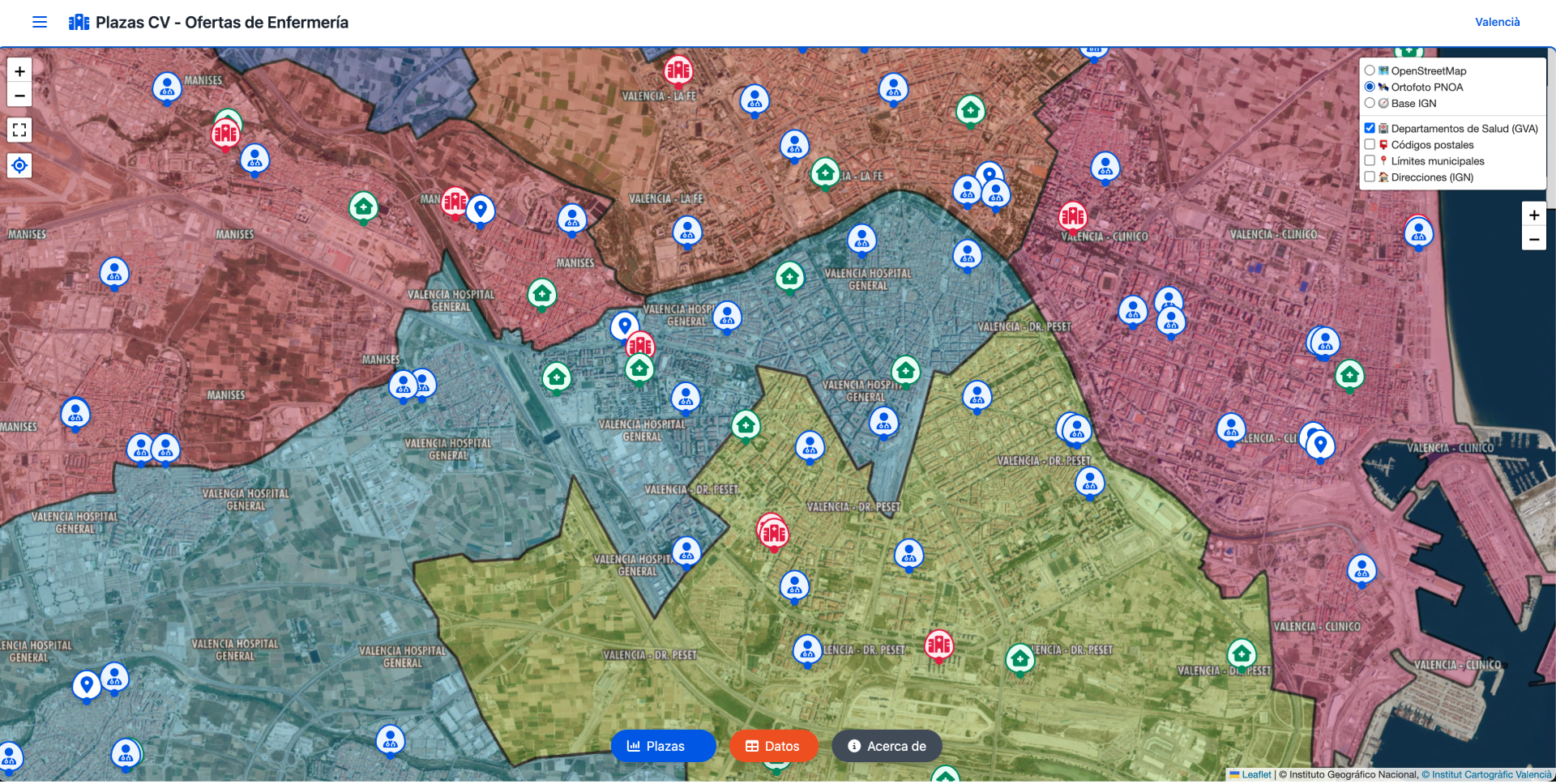
Visualización Geográfica Dinámica
El núcleo del visor es el mapa interactivo , implementado mediante Leaflet , una biblioteca ligera y poderosa para mapas web. El mapa carga dinámicamente los datos desde un archivo GeoJSON previamente procesado, que contiene información sobre la ubicación de cada centro sanitario, junto con el número de plazas adjudicadas.
Este mapa además de presentar el fichero con información de los centros en formato GeoJSON añade algunas capas más, de interés para el usuario.
Por ejemplo, permite pasar del visor clásico callejero de OpenStreetMap a una vista en modo fotografía aérea u ortofoto mediante la capa WMS del PNOA y también nos permite cargar una capa base del Instituto Geográfico Nacional . Por otro lado también muestra una capa de departamentos o áreas de salud de la Generalitat Valenciana bajo los que se gestiona cada centro sanitario y que se muestran en el mapa, permitiendo consultar de manera visual un área o centro sanitario a qué departamento de salud pertenece.
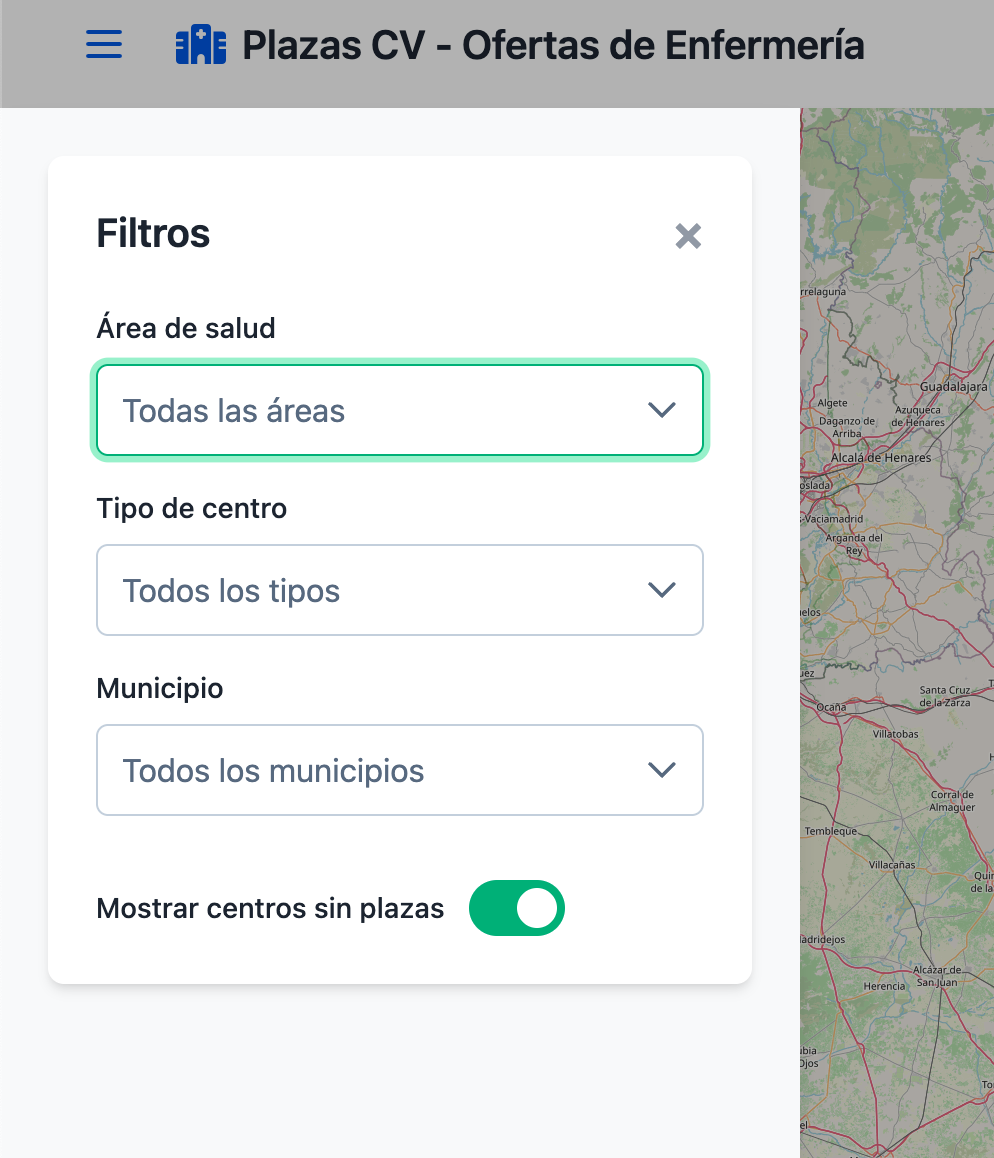
1. Filtrado dinámico y reactivo
El visor incluye un sistema de filtros avanzados que permite a los usuarios refinar los resultados según departamento de salud, municipio y tipo de centro sanitario. Esta funcionalidad es crucial para encontrar las plazas que realmente interesan sin perder contexto geográfico. El filtro se gestiona principalmente en FiltersDrawer.vue y usePlazas.js, asegurando que los cambios se reflejen en tiempo real en el mapa sin necesidad de recargas adicionales.
Características clave:
- Filtrado por área sanitaria: Los usuarios pueden seleccionar uno o varios departamentos para limitar los resultados a una región específica. Esto es útil para quienes prefieren trabajar cerca de casa o en un área específica.
- Filtrado por tipo de centro: Permite distinguir entre hospitales, centros de especialidades, centros de salud y consultorios auxiliares, cada uno con su propio icono distintivo.
- Filtrado por municipio: Ajusta los resultados a los municipios visibles en el mapa, con chips dinámicos que se actualizan al mover el viewport.
- Filtrado de vacantes: Elimina automáticamente los centros sin plazas disponibles para enfocar los resultados en las oportunidades abiertas.
Imagina a Carlos, un enfermero que quiere explorar las plazas disponibles en diferentes municipios para encontrar el lugar perfecto para trabajar cerca de su familia. Abre el visor en su portátil y, al instante, ve el panel de filtros en la parte inferior.
«Solo quiero ver los hospitales en València con plazas disponibles», se dice mientras ajusta los filtros.
- Carlos selecciona València en el filtro de municipios. El mapa responde al instante, mostrando solo los marcadores que coinciden con la ciudad de València.
- Luego, toca el filtrado de tipo de centro y marca Hospitales para eliminar centros de salud y consultorios auxiliares de su búsqueda. Los iconos azules desaparecen y los contadores de Plazas Ofertadas y Disponibles se recalculan al vuelo.
- Desactiva el filtro de vacantes ( mostrador centros sin plazas ) para eliminar los centros sin plazas disponibles, dejando solo los hospitales que aún tienen oportunidades abiertas.
De esta forma, Carlos puede filtrar los resultados con precisión, enfocándose solo en las plazas que realmente le interesan, sin tener que recargar la página o perder contexto geográfico.
Interacción en tiempo real:
Cada cambio en los filtros dispara eventos que se propagan a través de usePlazas.js, recalculando las plazas visibles y actualizando los contadores de plazas sin pérdida de contexto geográfico. Esto garantiza una experiencia fluida incluso en dispositivos móviles.
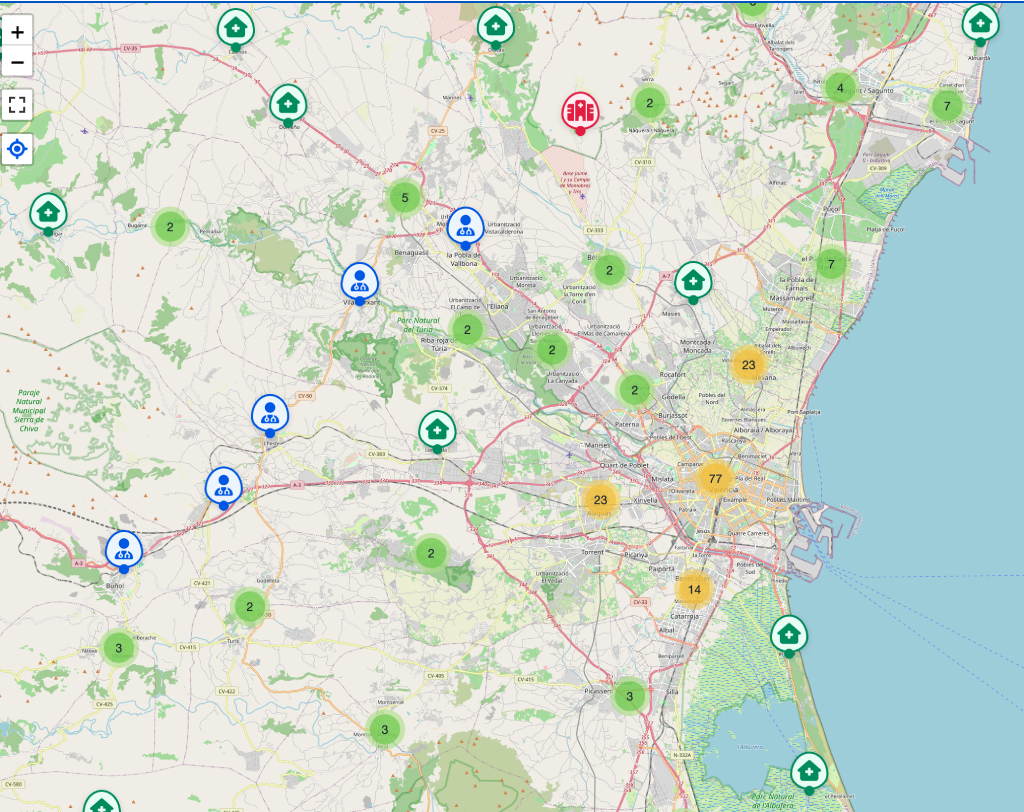
2. Mapa interactivo con clustering dinámico
El componente MapView.vue es el corazón del visor. Se encarga de cargar y renderizar las features almacenadas en centres.geojson usando Leaflet.MarkerCluster. Esto permite agrupar cientos de centros sanitarios sin sacrificar rendimiento, al tiempo que mantiene una representación clara y precisa a diferentes niveles de zoom.
Características clave:
- Clustering adaptativo: Agrupa los marcadores en clústeres cuando el usuario se aleja y los expande progresivamente al acercarse, evitando el solapamiento de íconos.
- Iconos personalizados: Los centros se representan con diferentes íconos según su tipo (hospital 🏥, centro de salud 🩺, consultorio 🏠), facilitando la identificación visual rápida.
- Capa base múltiple: Además del mapa callejero de OpenStreetMap, los usuarios pueden alternar a capas como las ortofotos del PNOA para un contexto geográfico más preciso.
- Compatibilidad móvil: El mapa responde fluidamente a toques y gestos de zoom en dispositivos móviles, manteniendo una tasa de frames alta incluso en dispositivos más antiguos.
El componente MapView.vue implementa el mapa de la aplicación, sobre el que se cargan las features almacenadas en el fichero centres.geojson usando Leaflet.MarkerCluster. Estas features o centros sanitarios se presentan con iconos diferenciados. Los marcadores se agrupan en clústeres o grupos de marcadores en los que el clustering se desactiva al acercarse, evitando solapamientos y manteniendo el rendimiento en móviles.
Vista del clústering de iconos sobre el mapa
Iconos diferenciados para cada tipo de centro sanitario
| Tipo de centro sanitario | Icono |
|---|---|
| Hospitales |  |
| Centros de Especialidades |  |
| Centros de Salud |  |
| Consultorios Auxiliares |  |
3. Popup de detalle de centro
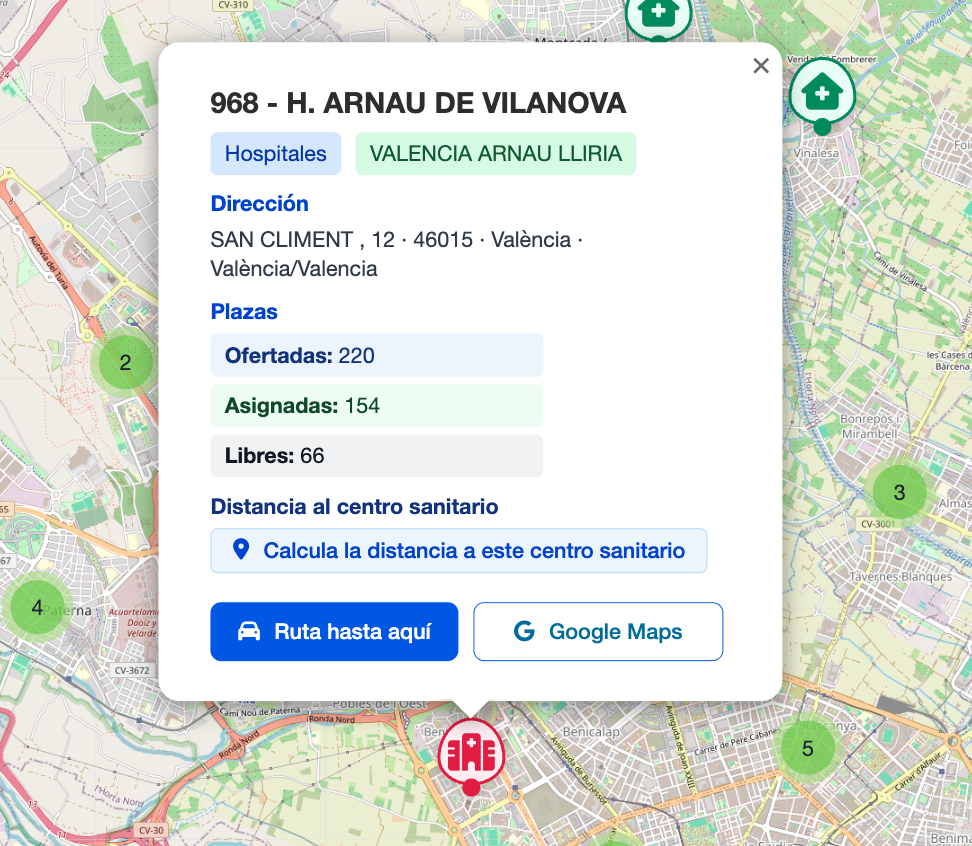
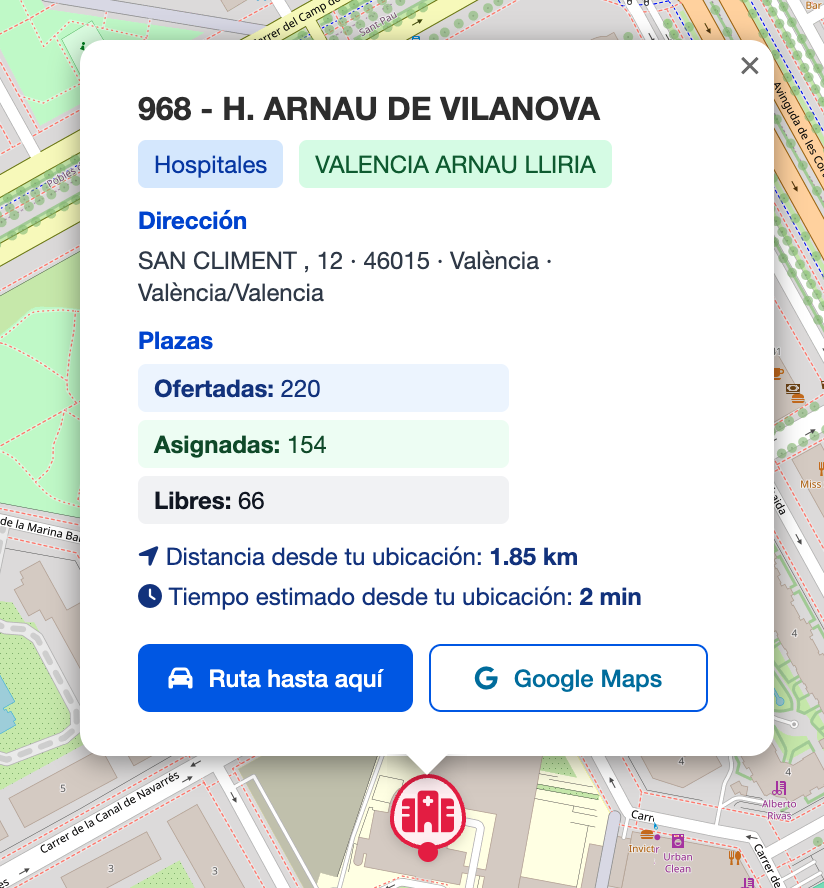
Cuando el usuario pulsa sobre un marcador, MapView.vue despliega un L.Popup enriquecido que concentra toda la información relevante del centro seleccionado:
| Elemento | Descripción |
| Título | Código + nombre del centro en negrita para identificarlo al instante. |
| Badges contextuales | Dos píldoras de color que indican tipo de centro (p.ej. “Hospitales”) y departamento (p.ej. “VALENCIA ARNAU LLIRIA”). |
| Dirección completa | Calle, número, CP, municipio y provincia en una sola línea legible. |
| Plazas | Información de las plazas ofrecidas, asignadas y restantes o libres en el centro sanitario |
| Distancia | Cálculo en tiempo real desde la posición del usuario hasta el centro (en km). |
| Tiempo estimado | Estimación de minutos en coche usando la API de enrutado del navegador / dispositivo. |
| Botón “Ruta hasta aquí” | Muestra la ruta hasta el centro sanitario pre‑rellenada. |
| Botón “Google Maps” | Abre Google Maps con la ubicación del centro sanitario |
4. Panel flotante de KPIs: la brújula interactiva
Imagina a Ana, una enfermera que prepara sus preferencias de destino antes de la adjudicación definitiva. Abre el visor en su móvil mientras viaja en metro y, nada más cargar el mapa, se despliega un panel translúcido al pie de la pantalla.
«Quiero ver solo los hospitales que quedan cerca de casa», piensa.
El FloatingStatsPanel.vue se desliza en la parte inferior del mapa y combina filtros rápidos con indicadores clave de plazas:
| Zona | Funcionalidad |
|---|---|
| Departamentos de Salud | Chips seleccionables que limitan la vista a uno o varios departamentos. Cuando hay más de 4 valores, aparece el botón «+ n más» que abre un popover con el resto. |
| Municipios | Segunda fila de chips con los municipios presentes en el viewport. Se actualizan dinámicamente al mover el mapa. |
| Tipos de Centro | Etiquetas coloreadas que resumen el recuento de centros visibles por categoría (Hospitales, Centros de Especialidades, Centros de Salud, Consultorios, Otros). El color coincide con el icono del mapa. |
| Plazas | Cuadro de métricas alineado a la derecha: • Ofertadas (total publicado en la convocatoria). • Asignadas (plazas ya adjudicadas). • Disponibles (vacantes restantes). Todos los valores cambian en tiempo real según filtros y extensión de mapa. |
| Botón de colapso | Un icono «🡇» permite minimizar el panel para maximizar el área del mapa en móviles. El estado se persiste en localStorage. |
5. Panel de Datos en Bruto
El RawDataPanel.vue es una tabla interactiva que permite a los usuarios explorar todos los datos sin depender de la vista de mapa. Esta tabla es ideal para quienes quieren realizar análisis más detallados o exportar los datos para un procesamiento externo en Excel o herramientas de análisis de datos.
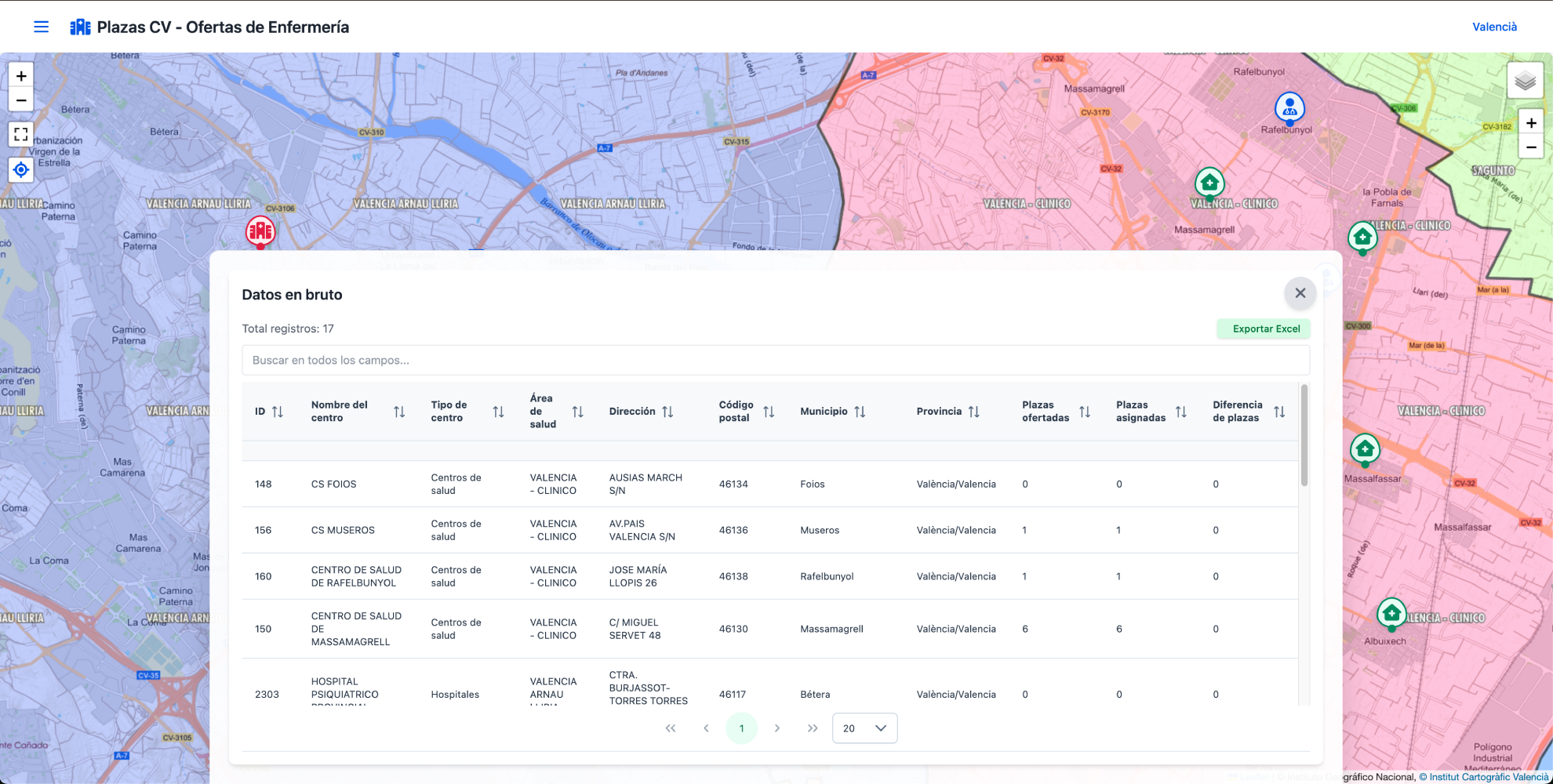
Características clave:
- Búsqueda global: Un campo de búsqueda en la parte superior permite filtrar registros en tiempo real. Los términos ingresados se comparan contra todas las columnas, facilitando encontrar centros específicos rápidamente.
- Ordenación por columnas: Los usuarios pueden ordenar cada columna haciendo clic en los encabezados, permitiendo organizar los datos según ID, nombre del centro, tipo, departamento, municipio, código postal o plazas disponibles.
- Paginación dinámica: Para mejorar el rendimiento y la navegación, los resultados se dividen en páginas con tamaños ajustables (p.ej. 10, 20, 50 registros por página).
- Exportación rápida: Un botón en la esquina superior derecha permite exportar todos los registros filtrados a un archivo Excel para un análisis más profundo.
- Diseño responsive: El panel se adapta a diferentes tamaños de pantalla, manteniendo una experiencia de usuario consistente en dispositivos móviles.
Interacción con otros componentes:
- Los filtros aplicados en el mapa (departamentos, tipos de centro, municipios) también afectan los resultados visibles en el panel de datos en bruto, garantizando que siempre se muestre información coherente.
- Los cambios en el panel de datos se reflejan en los gráficos y KPIs del panel flotante, asegurando que toda la interfaz esté sincronizada.
Optimización para rendimiento:
El panel está optimizado para manejar grandes volúmenes de datos sin degradar la experiencia del usuario, utilizando técnicas como carga diferida (lazy loading) y virtualización para reducir el impacto en la memoria y el tiempo de renderizado.
Repositorio del Proyecto en GitHub
El código fuente completo del visor interactivo de plazas de enfermería está disponible en GitHub. Esto permite a otros desarrolladores explorar, colaborar y personalizar el visor según sus necesidades.
👉 Repositorio del Visor de Plazas de Enfermería GVA: https://github.com/andreums/visor_ope_enfermeria_gva_2022
¿Qué encontrarás en el repositorio?
- Componentes Reutilizables: Estructura de componentes como
MapView.vue,FiltersDrawer.vueyFloatingStatsPanel.vuepara una integración rápida. - Lógica de Negocio Encapsulada: Composables como
usePlazas.jspara manejar datos de centros sanitarios de forma eficiente. - Estilos Optimizados: Configuración de Tailwind CSS para interfaces rápidas y responsivas.
- Internacionalización: Soporte para múltiples idiomas para facilitar la localización.
- Despliegue Continuo: Configuración para despliegue automático en GitHub Pages.
Pasos para Compilar y Ejecutar el Proyecto Localmente
- Clona el repositorio desde GitHub:
git clone https://github.com/andreums/visor_ope_enfermeria_gva_2022.git
cd visor_ope_enfermeria_gva_2022
2. Instala las dependencias del proyecto:
npm install3. Ejecutar el Proyecto en Modo Desarrollo
npm run devEl proyecto estará disponible en http://localhost:5173 (o el puerto configurado en vite.config.js).
4. Compila el proyecto para producción
npm run buildEsto generará una versión optimizada del proyecto en la carpeta dist/, lista para ser desplegada en GitHub Pages o cualquier otro servidor estático.
🚀 Posibles Ampliaciones
El proyecto tiene un gran potencial para crecer y adaptarse a nuevas necesidades. Algunas ideas para futuras mejoras incluyen:
- Favoritos y estudios personalizados: Incluir una funcionalidad para que el usuario pueda guardarse determinados centros como favoritos y crear estudios o simulaciones en base a dichos favoritos.
- Visualización 3D y Capas Avanzadas: Incluir capas tridimensionales para mejorar la percepción geográfica de los centros.
- Visualización 3D y Capas Avanzadas: Incluir capas tridimensionales para mejorar la percepción geográfica de los centros.
- Historial de Cambios: Permitir a los usuarios ver cómo ha cambiado la disponibilidad de plazas a lo largo del tiempo.
- Autenticación de Usuarios: Crear perfiles personalizados para que los usuarios puedan guardar filtros y preferencias.
Estas mejoras no solo aumentarían la funcionalidad del visor, sino que también lo convertirían en una herramienta aún más poderosa para la gestión de datos sanitarios a gran escala.
Lecciones Aprendidas
Desarrollar el visor interactivo de plazas de enfermería para la Comunitat Valenciana fue un proyecto desafiante que me permitió explorar diversas tecnologías y superar obstáculos técnicos que, aunque complejos, resultaron ser oportunidades para aprender y mejorar. A continuación, comparto algunas de las lecciones más importantes que he aprendido a lo largo del proceso:
- Manejo de Datos Públicos
Trabajar con datos públicos implica lidiar con formatos inconsistentes y datos faltantes. En este caso, las fuentes de datos variaban en estructura y calidad, requiriendo un proceso intensivo de limpieza y transformación para crear un dataset unificado y preciso. - Optimización del Rendimiento
Al tratar con grandes volúmenes de datos geoespaciales, el rendimiento es clave. Opté por estrategias como el uso de clústeres en Leaflet para agrupar marcadores, lo que mejoró significativamente la velocidad de carga y la experiencia del usuario. - Interactividad y Usabilidad
Diseñar una interfaz intuitiva es tan importante como el backend que alimenta los datos. Integrar Vue.js y PrimeVue para crear componentes reutilizables fue fundamental para lograr una experiencia fluida y visualmente atractiva. - Despliegue y Escalabilidad
Publicar la aplicación en GitHub Pages requirió optimizar los tiempos de compilación y carga, además de asegurarse de que el visor sea responsive para dispositivos móviles. Esto implicó un trabajo continuo en la configuración de Vite y Tailwind para lograr tiempos de respuesta rápidos incluso en conexiones lentas. - Gestión del Estado y Datos en Tiempo Real
Implementar filtros dinámicos y actualizar estadísticas en tiempo real requirió una arquitectura clara para manejar los cambios de estado en el frontend sin sobrecargar el navegador. - Colaboración y Documentación
Trabajar en un proyecto de código abierto requiere una documentación clara para facilitar la colaboración. Esto incluye no solo comentarios en el código, sino también guías para contribuir y configurar el entorno de desarrollo.
Espero que estas lecciones puedan servir de inspiración para otros desarrolladores que se enfrenten a proyectos similares. Como siempre, la clave está en iterar, aprender y nunca dejar de optimizar.
Conclusiones
El desarrollo de este visor de plazas de enfermería representa un paso importante hacia la democratización del acceso a datos sanitarios en la Comunitat Valenciana. Transformar datos crudos, dispersos y difíciles de analizar en una herramienta intuitiva y accesible no solo mejora la transparencia, sino que empodera a miles de profesionales sanitarios para tomar decisiones informadas sobre su futuro laboral.
Impacto del Proyecto:
- Empoderamiento del Usuario: Permite a los profesionales sanitarios explorar datos geográficos y de plazas sin necesidad de conocimientos avanzados en análisis de datos o cartografía.
- Reducción de Barreras Técnicas: Elimina la necesidad de herramientas complejas para acceder a datos públicos, promoviendo una toma de decisiones más rápida y precisa.
- Transparencia y Confianza: Mejora la transparencia en la gestión de plazas sanitarias, fortaleciendo la confianza entre los ciudadanos y las instituciones públicas.
- Optimización de Procesos: Reduce la carga administrativa para los departamentos de salud al ofrecer una plataforma autosuficiente para la consulta de datos.
- Innovación en Datos Abiertos: Demuestra cómo las administraciones públicas pueden utilizar tecnología de código abierto para modernizar sus servicios y hacer que los datos sean realmente útiles para todos.
Reflexión Final:
En tiempos donde la digitalización avanza rápidamente, proyectos como este son fundamentales para cerrar la brecha entre los datos y sus usuarios. Crear herramientas accesibles no solo mejora la eficiencia operativa, sino que también promueve una cultura de transparencia, colaboración y toma de decisiones basadas en datos.
Este visor es solo el comienzo. Con futuras mejoras, podría convertirse en una referencia para otras aplicaciones gubernamentales, ayudando a transformar cómo se gestionan y visualizan los datos públicos.
¡Participa y Colabora!
Si este proyecto te ha resultado útil o inspirador, ¡no dudes en unirte a la comunidad! Aquí hay algunas formas en las que puedes contribuir o seguir explorando:
- Explora el visor interactivo : Prueba tú mismo el visor de plazas de enfermería aquí y descubre cómo puede ayudarte a tomar decisiones informadas.
- Accede al código fuente : Todo el código utilizado en este proyecto está disponible en nuestro repositorio de GitHub . Siéntete libre de revisarlo, mejorarlo o adaptarlo a tus necesidades.
- Comparte tus ideas : ¿Tienes sugerencias para mejorar el visor? ¿O quizás una nueva funcionalidad en mente? Déjame un comentario más abajo o contáctanos a través de email andresmartinezsoto at gmail punto com.
- Apoya el proyecto : Si crees que esta herramienta puede beneficiar a más personas, compártela con tus colegas, amigos o redes profesionales. Juntos podemos democratizar el acceso a la información.
¡Tu participación es clave para seguir mejorando este proyecto y hacerlo aún más útil para todos!




