Introducción
En la Comunitat Valenciana, como en muchas otras regiones, las plazas vacantes para personal de enfermería se publican mediante resoluciones oficiales en formato PDF. Son documentos técnicamente públicos, sí, pero muy poco prácticos: sin buscador, sin filtros, sin mapas. Solo cientos de páginas de texto que convierten lo que debería ser una consulta sencilla en una auténtica odisea.
Todo empezó porque mi pareja —enfermera— y varios amigos del sector me enseñaron uno de esos PDFs. Cada vez que se publica un nuevo concurso de OPE —ya sea por examen o por consolidación—, se ven obligados a buscar una plaza cerca de casa entre decenas (o cientos) de páginas, sin filtros, sin buscador y sin mapas. Una locura.
Muchos dedican horas a revisar resoluciones, tomar notas a mano, buscar municipios en Google Maps… y aun así, no consiguen tener una visión clara del panorama real de vacantes. Y todo para poder acercarse a su casa, estabilizarse en su plaza o simplemente cambiar de área de salud.
Como desarrollador, me dije: esto se puede mejorar. Decidí aplicar lo que sé de Python, datos abiertos y mapas interactivos para ayudarles —y de paso, ayudarme a mí mismo— a convertir ese caos en algo útil: un visor web de plazas geolocalizadas, con filtros, estadísticas y visualización inmediata.
Y aquí viene la paradoja: vivimos en una época donde se promueve la reutilización de datos públicos, pero muchas administraciones siguen publicando información clave en formatos cerrados, no estructurados y difíciles de automatizar. Aunque existen portales de datos abiertos, a menudo los datos no están disponibles en formatos realmente reutilizables. El resultado: se limita su impacto real en la sociedad.
En esta primera parte te cuento cómo pasé de un PDF inmanejable a un dataset limpio y georreferenciado. Esta base de datos servirá para algo mucho más potente, que verás en la Parte 2: el desarrollo completo de un visor interactivo con Vue.js y Leaflet.
✅ TL;DR – Resumen rápido del proyecto (Parte 1)
Cada vez que se publican nuevas plazas de OPE para personal de enfermería en la Comunitat Valenciana, la Conselleria lo hace en forma de PDF largo, sin filtros ni buscador. Esto hace que localizar una plaza cercana sea un infierno.
👉 Como desarrollador (y pareja de una enfermera), decidí convertir esos PDFs en datos geolocalizados, visualizables en un mapa con filtros y estadísticas.
📌 En esta Parte 1, explico cómo extraje y limpié los datos con Python y pdfplumber, cómo los geolocalicé usando datasets abiertos y cómo los dejé listos para visualizar en una app web.
TABLA DE CONTENIDOS
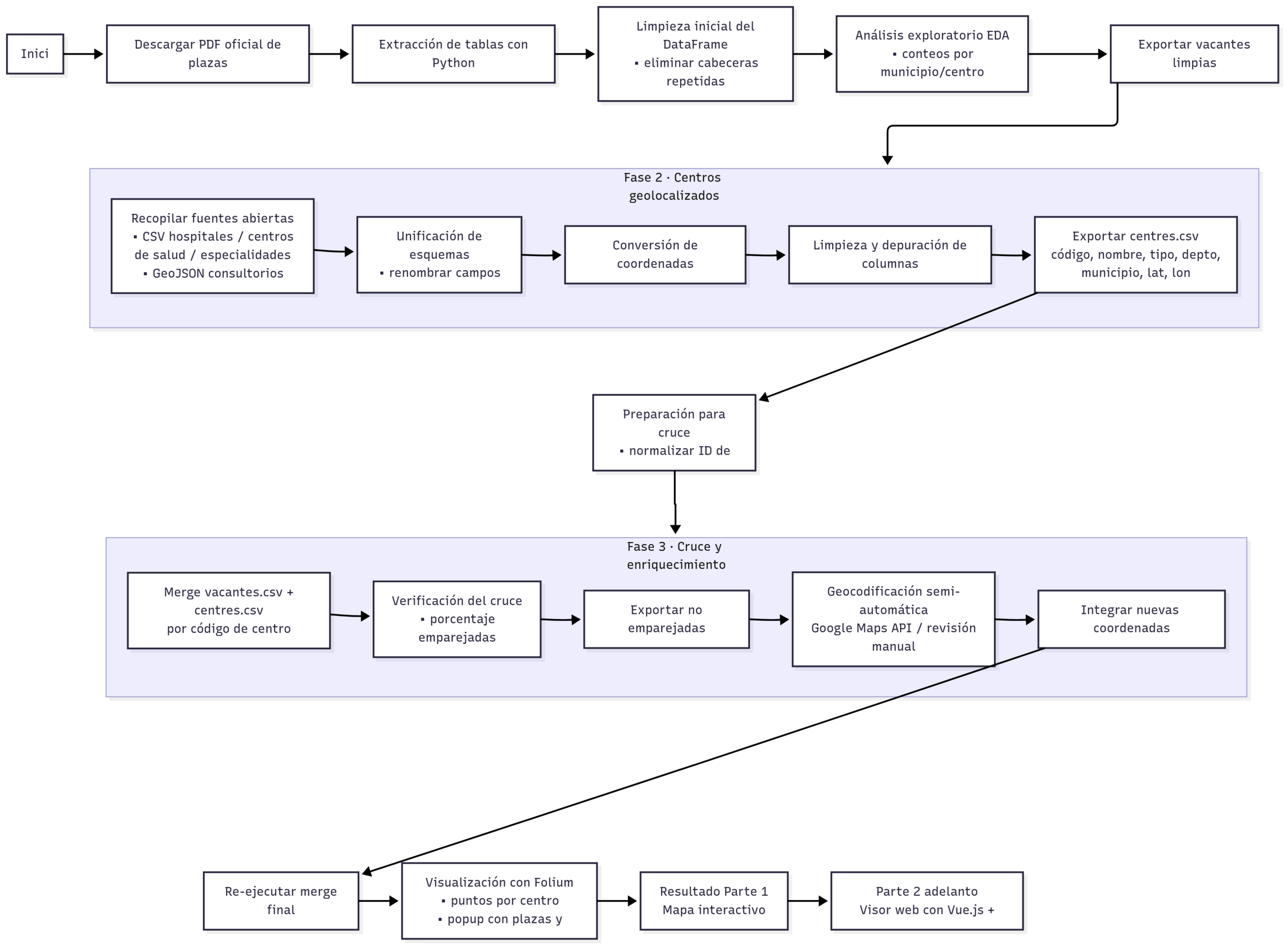
0. ¿Qué vamos a hacer exactamente?
Antes de meternos en harina, pongamos el plan sobre la mesa.
Nuestro objetivo es transformar un PDF oficial con las plazas de OPE (oferta pública de empleo) en un visor web interactivo, donde se pueda consultar fácilmente dónde hay vacantes, cuántas hay y en qué tipo de centro se encuentran (hospital, centro de salud, consultorio…).
Para conseguirlo, vamos a aplicar un enfoque de ciencia de datos en varias fases:
- Extraer las plazas desde el PDF (¡sí, ese tocho infumable que publica la Conselleria!).
- Limpiar y estructurar los datos en un DataFrame usable.
- Geolocalizar los centros sanitarios combinando varias fuentes públicas (CSV y GeoJSON).
- Unir las vacantes con su localización real (lat/lon).
- Completar a mano lo que falte usando la API de Google Maps.
- Y, finalmente, mostrarlo todo en un mapa interactivo con Folium.
Esto es la Parte 1. En la Parte 2 (muy pronto 👀), construiremos el visor frontend con Vue.js y Leaflet, listo para usarse por cualquier enfermero o enfermera que esté buscando plaza cerca de casa.
1. Extracción de datos desde el PDF
Todo gran proyecto de datos empieza con una pregunta sencilla… y un archivo poco amigable.
En este caso, el punto de partida era un PDF oficial con más de 300 páginas y cientos de líneas de texto plano, donde se recogen las plazas de OPE para personal de enfermería en la Comunitat Valenciana. Sin buscador, sin estructura, sin formato reutilizable. Un laberinto de información que hace imposible encontrar rápidamente una plaza concreta en un municipio específico.
La misión era clara: convertir ese PDF en un conjunto de datos estructurado, legible y procesable. Solo así podríamos empezar a trabajar en filtros, visualizaciones o mapas interactivos.
En las siguientes secciones te cuento paso a paso cómo pasé de un documento caótico a un DataFrame de Pandas limpio y preparado para análisis, combinando Python, pdfplumber, y un poco de paciencia.
1.1 De un PDF imposible… a algo que se pueda trabajar
imer reto era evidente: extraer información útil de un PDF que no estaba pensado para ser leído por máquinas… ni casi por personas. La Conselleria de Sanitat publica estas resoluciones en un documento plano, extenso y sin estructura clara. Cada página contiene tablas, sí, pero están formateadas de forma irregular, sin delimitadores fiables, y con cabeceras que se repiten (y a veces varían) de una página a otra.
Nada de CSV. Nada de Excel. Nada de API. Solo texto incrustado en un PDF generado desde un procesador de textos, en un formato que no facilita para nada la reutilización o el análisis automático.
Antes de pensar en mapas, filtros o visualizaciones, había que atacar el problema de raíz: convertir ese PDF caótico en una tabla estructurada con columnas claras, filas consistentes y sin datos erróneos. En resumen: hacer que esos datos fueran útiles y tratables con Python.
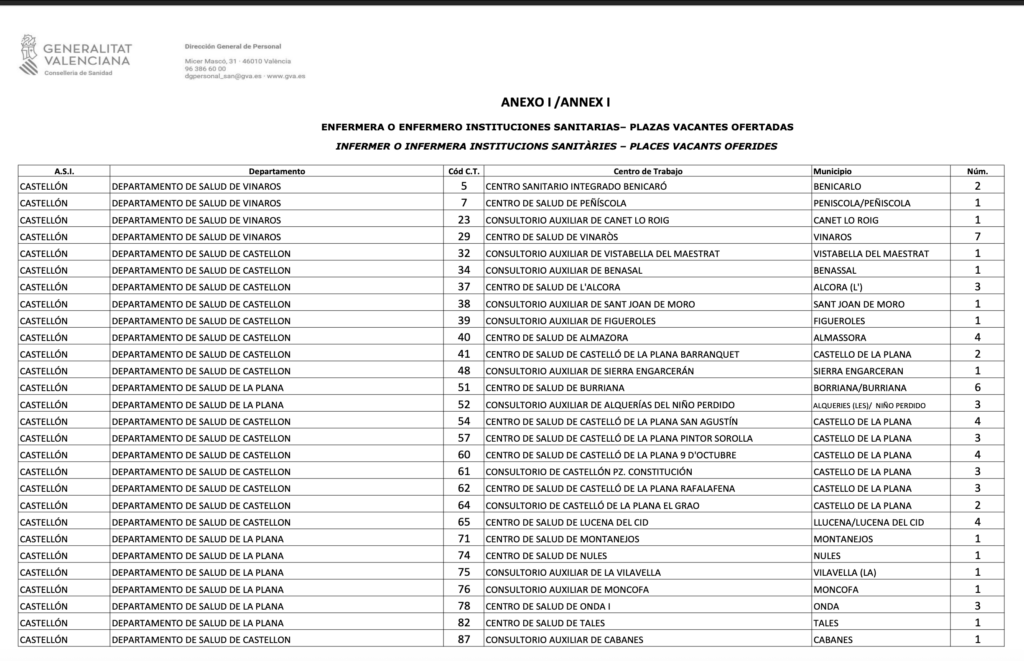
El documento, tras eliminar los datos personales por protección de datos, tiene una tabla con seis columnas principales:
- A.S.I.: Área de Salud Integrada.
- Departamento: Nombre del departamento de salud.
- Cód. C.T.: Código del centro sanitario (clave para cruzar con coordenadas después).
- Centro de Trabajo: Nombre del centro donde se ofrece la plaza.
- Municipio: Localidad en la que está ubicado.
- Núm.: Número de plazas ofertadas.
Una vez identificadas estas columnas, el objetivo era claro: extraer esas tablas página por página y volcar los datos en un DataFrame de Pandas que sirviera como base para todo lo que vendría después.
Antes de pensar en mapas o gráficos, era imprescindible convertir este contenido no estructurado en una estructura de datos útil y analizable.
1.2 Primera aproximación: extracción con Python y pdfplumber
Una vez en la mano el PDF, tocaba meterle mano con herramientas de verdad. La elegida fue pdfplumber, una librería de Python especialmente útil cuando se trata de extraer tablas directamente desde documentos PDF, conservando su estructura visual.
A diferencia de otras soluciones como PyPDF2, que se limitan a sacar texto plano sin respetar columnas ni filas, pdfplumber nos permite acceder a tablas completas, leerlas como listas de listas, e incluso detectar automáticamente cabeceras y celdas.
La idea era sencilla: convertir cada página del PDF en una tabla de datos, donde cada fila representara una plaza (o conjunto de plazas) con su información correspondiente: centro, municipio, departamento, y número de plazas.
Con unas pocas líneas de código, el script recorre todas las páginas, detecta la tabla principal en cada una, salta la cabecera repetida y va acumulando datos en una lista. Al final, ese contenido se vuelca a un DataFrame de pandas, lo que nos permite empezar a trabajar de forma mucho más flexible con los datos.
Este fue el primer paso real para domesticar un documento pensado solo para ser leído a ojo, y convertirlo en algo con lo que podamos trabajar programáticamente. Y créeme: fue más sencillo de lo que parecía al principio.
import pdfplumber
import pandas as pd
import re
pdf_path = "data/places.pdf"
csv_path_raw = "data/plazas_raw_simple.csv"
csv_path_cleaned = "data/plazas_cleaned_simple.csv"
data = []
headers_raw = None
print(f"Extrayendo datos (método simple) desde: {pdf_path}")
with pdfplumber.open(pdf_path) as pdf:
for i, page in enumerate(pdf.pages):
table = page.extract_table()
if table:
if headers_raw is None:
headers_raw = table[0]
print(f" Cabeceras detectadas (crudas): {headers_raw}")
data.extend(table[1:]) # Saltamos la cabecera
else:
data.extend(table[1:]) # Asumimos cabecera repetidaEste bloque abre el PDF, recorre todas las páginas y extrae la tabla principal por página. El script asume que hay una única tabla por página y que la primera fila contiene la cabecera (normalmente repetida en cada página).
🧹 Limpieza inicial de datos
Una vez tenemos las tablas extraídas del PDF, toca lo de siempre: limpiar.
Aunque pdfplumber nos da una estructura bastante decente, lo que sale del PDF no es perfecto. Hay cabeceras mal formateadas, celdas con saltos de línea, espacios en blanco innecesarios o valores vacíos. Así que el siguiente paso fue aplicar un poco de cariño con pandas.
Primero, limpiamos los nombres de las columnas:
- Eliminamos saltos de línea (
\n) - Quitamos espacios de más
- Y, si falta algún nombre, lo sustituimos por
col_0,col_1…
Después, hacemos lo mismo con las celdas de datos:
- Convertimos todos los valores a texto
- Borramos saltos de línea y espacios sobrantes
- Y marcamos como
Noneaquellas celdas vacías (que suelen venir como""o espacios en blanco)
El resultado es un DataFrame más limpio, legible y listo para procesar. Nada espectacular, pero sin esta parte, todo lo que viene después sería mucho más difícil (y propenso a errores invisibles).
En resumen: limpiar los datos no es glamuroso, pero es fundamental. Y aquí nos dejó todo listo para seguir con renombrado de columnas, validaciones y más transformaciones.
# 🔠 Limpiar cabeceras: quitar saltos de línea y espacios, o asignar nombre genérico si está vacía
headers_cleaned = [
str(h).replace('\n', ' ').strip() if h else f'col_{j}'
for j, h in enumerate(headers_raw)
]
# 🧱 Crear el DataFrame con las cabeceras limpias
df = pd.DataFrame(data, columns=headers_cleaned)
# 🧼 Limpiar los valores: eliminar saltos de línea, espacios extra y celdas vacías
df = df.applymap(lambda x: str(x).replace('\n', ' ').strip() if isinstance(x, str) else x)
# Sustituir celdas vacías (espacios, cadenas vacías…) por None
df.replace(r'^\s*$', None, regex=True, inplace=True)
✅ Consejo para lectores técnicos:
applymap()se aplica a todo el DataFrame, lo cual es más limpio quemap()en este caso, ya quemap()está pensado para Series. Aquí así garantizamos que cada celda de texto queda pulida.
🗂 Renombrado de columnas
El CSV extraído directamente desde el PDF suele venir con nombres de columna poco claros, demasiado largos o inconsistentes. Para facilitar el análisis y los pasos siguientes del proceso, lo ideal es asignar nombres semánticos y normalizados desde el principio.
Esto no solo mejora la legibilidad del código, sino que permite trabajar de forma más robusta en los siguientes pasos: extracción de códigos, filtrado, agrupación por zonas, geolocalización, etc.
Aquí va una primera validación de columnas y su renombrado:
# 🔢 Comprobamos si el número de columnas coincide con lo esperado
expected_num_columns = 5
if len(df.columns) == expected_num_columns:
rename_map = {
df.columns[0]: 'ASI', # Área de Salud Integrada
df.columns[1]: 'Departamento', # Nombre del departamento de salud
df.columns[2]: 'Centro_Codigo_Raw', # Texto combinado del centro y su código
df.columns[3]: 'Municipio', # Localidad donde está el centro
df.columns[4]: 'Num_Plazas_Str' # Número de plazas vacantes (como texto)
}
df.rename(columns=rename_map, inplace=True)
print("✅ Columnas renombradas:", df.columns.tolist())
else:
print(f"⚠️ Se esperaban {expected_num_columns} columnas, pero se encontraron {len(df.columns)}.")
Una vez hecho este renombrado, ya tenemos un DataFrame estructurado y mucho más fácil de manejar, sobre el que podremos aplicar transformaciones posteriores: normalizar nombres, separar códigos, unir con otros datasets y construir las visualizaciones interactivas.
💾 Guardado del resultado
Una vez extraídos y limpiados los datos desde el PDF, toca guardar los resultados para poder seguir trabajando cómodamente más adelante.
Se generan dos archivos .csv:
plazas_raw_simple.csv👉 contiene los datos tal como se han extraído del PDF, estructurados pero sin transformación profunda.plazas_cleaned_simple.csv👉 mismo contenido, pero con cabeceras renombradas y preparadas para su análisis y procesamiento posterior.
# Guardamos ambos archivos CSV
df.to_csv(csv_path_raw, index=False, encoding="utf-8") # Datos estructurados
df.to_csv(csv_path_cleaned, index=False, encoding="utf-8") # Con nombres de columnas limpios
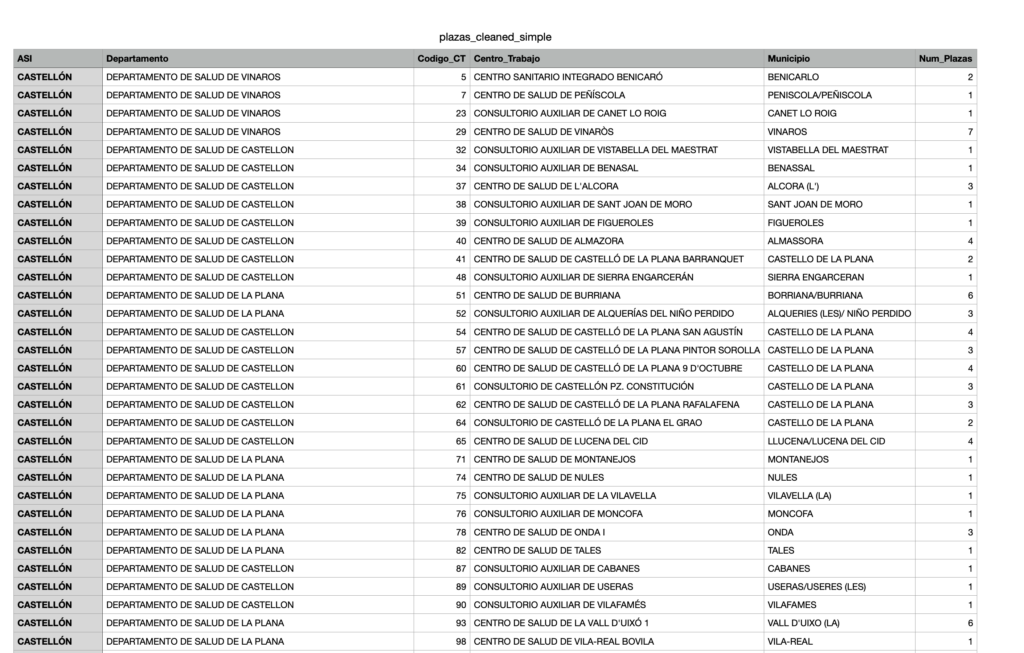
✅ Resultado del Paso 1: Vacantes extraídas correctamente
Gracias a la librería pdfplumber, conseguimos transformar un PDF poco amigable en un DataFrame estructurado y procesable, donde cada fila representa una plaza vacante publicada por la Conselleria de Sanitat.
Las columnas detectadas y renombradas incluyen información clave como:
| Campo en PDF | Significado |
|---|---|
| Núm. | Número de plazas ofertadas |
| A.S.I. | Área de Salud Integrada |
| Departamento | Nombre del departamento de salud (ej. «VALENCIA – CLÍNICO») |
| Cód C.T. | Código identificador del centro de trabajo |
| Centro de Trabajo | Nombre del centro donde se ofrece la plaza (ej. «CENTRO DE SALUD XIRIVELLA») |
| Municipio | Localidad donde está ubicado el centro |
Este dataset, que antes estaba enterrado entre cientos de páginas de un PDF poco accesible, ya está listo para empezar a trabajar con él de verdad: hacer análisis, unir con otras fuentes y visualizarlo en un mapa.
Hemos guardado dos versiones del CSV:
plazas_raw_simple.csv: estructura básica, útil para trazabilidad o depuración.plazas_cleaned_simple.csv: con nombres de columnas limpios y preparados para los siguientes pasos.
A partir de aquí, ya podemos empezar a explorar el contenido, verificar su calidad y comprobar si la extracción se ha realizado correctamente.
📸 Vista previa de las primeras filas extraídas:
import pdfplumber
import pandas as pd
import re
# Rutas de entrada y salida
pdf_path = "data/places.pdf"
csv_path_raw = "data/plazas_raw_simple.csv"
csv_path_cleaned = "data/plazas_cleaned_simple.csv"
# Inicializamos variables
data = []
headers_raw = None
print(f"📥 Abriendo PDF: {pdf_path}")
# Abrimos el PDF y recorremos sus páginas
with pdfplumber.open(pdf_path) as pdf:
for i, page in enumerate(pdf.pages):
table = page.extract_table()
if table:
if headers_raw is None:
headers_raw = table[0]
print(f"🔍 Cabeceras detectadas en página {i + 1}: {headers_raw}")
data.extend(table[1:]) # Omitimos la cabecera
else:
data.extend(table[1:]) # Solo añadimos filas
# Validamos que se ha extraído algo
if not data or headers_raw is None:
raise ValueError("❌ No se han podido extraer datos válidos del PDF.")
# 🧹 Limpieza de cabeceras
headers_cleaned = [
str(h).replace('\n', ' ').strip() if h else f'col_{j}'
for j, h in enumerate(headers_raw)
]
# Creamos el DataFrame
df = pd.DataFrame(data, columns=headers_cleaned)
# Limpieza de contenido: quitar saltos de línea y espacios
df = df.applymap(lambda x: str(x).replace('\n', ' ').strip() if isinstance(x, str) else x)
df.replace(r'^\s*$', None, regex=True, inplace=True)
# 🗂 Renombrado de columnas si son las esperadas
expected_num_columns = 6
if len(df.columns) == expected_num_columns:
rename_map = {
df.columns[0]: 'Num_Plazas',
df.columns[1]: 'ASI', # Área de Salud Integrada
df.columns[2]: 'Departamento',
df.columns[3]: 'Codigo_CT', # Código del centro de trabajo
df.columns[4]: 'Centro_Trabajo',
df.columns[5]: 'Municipio'
}
df.rename(columns=rename_map, inplace=True)
print(f"✅ Columnas renombradas: {list(df.columns)}")
else:
print(f"⚠️ Número de columnas inesperado: {len(df.columns)}")
# 💾 Guardamos los resultados
df.to_csv(csv_path_raw, index=False, encoding="utf-8")
df.to_csv(csv_path_cleaned, index=False, encoding="utf-8")
print("📁 Archivos guardados:")
print(f" • CSV original: {csv_path_raw}")
print(f" • CSV limpio: {csv_path_cleaned}")
🔍 1.3 Análisis exploratorio: ¿Qué nos dicen los datos?
Antes de seguir avanzando, toca hacer algo esencial: pararnos un momento a mirar con lupa lo que acabamos de extraer. Ya tenemos nuestro DataFrame limpio, sí… pero ¿es fiable? ¿Tiene sentido lo que contiene? ¿Se ha capturado todo bien desde el PDF?
Este análisis exploratorio básico nos ayuda a responder a esas preguntas y a validar que el trabajo realizado hasta ahora va por buen camino. Además, nos permite empezar a entender el paisaje de las vacantes: cuántas hay, dónde se concentran y si hay algo que «huele raro».
Algunos aspectos que queremos revisar:
- ¿Los nombres de municipios y centros están bien capturados?
- ¿Los números de plazas tienen sentido o hay errores evidentes?
- ¿Existen duplicados, filas vacías o mal formateadas?
Para responder a esto de forma rápida y visual, generamos unos cuantos gráficos sencillos con Python, Pandas y Seaborn, que nos permiten ver:
- Los municipios con mayor número de plazas disponibles.
- Qué áreas de salud o provincias concentran más oferta.
- Posibles errores de escritura o codificación en los nombres.
Este paso es como levantar la tapa del motor antes de seguir conduciendo: si hay algo que chirría, es mejor detectarlo ahora que más adelante cuando estemos montando el visor.
En resumen: es una revisión rápida, pero clave, para asegurarnos de que los datos tienen la calidad mínima necesaria para construir algo sólido sobre ellos. Y de paso, empezamos a vislumbrar patrones que nos serán útiles en los próximos pasos del proyecto.
📊 ¿Dónde están las plazas?
Una vez hemos extraído y limpiado los datos del PDF, llega el momento de ver qué pinta tienen. ¿Dónde se concentran más plazas? ¿Hay municipios con muchas vacantes y otros sin apenas oferta? ¿Todo parece en orden o hay valores sospechosos?
Este análisis visual rápido —lo que en ciencia de datos llamamos EDA (Exploratory Data Analysis)— nos ayuda a comprobar que los datos tienen sentido, están completos, y que no se ha colado ningún error durante la extracción.
✅ ¿Qué miramos exactamente?
- Si hay municipios con muchas (o pocas) plazas → para detectar posibles errores o anomalías.
- Qué áreas de salud concentran más vacantes.
- Si hay fallos de codificación, nombres mal escritos o datos extraños.
Y para hacerlo más fácil de digerir, usamos unos gráficos de barras con Seaborn y Matplotlib que nos permiten ver, de un vistazo, cómo se distribuyen las vacantes por territorio.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Cargar el CSV limpio
df = pd.read_csv("data/plazas_cleaned_simple.csv")
# Asegurar que la columna de plazas es numérica
df["Num_Plazas"] = pd.to_numeric(df["Num_Plazas"], errors="coerce")
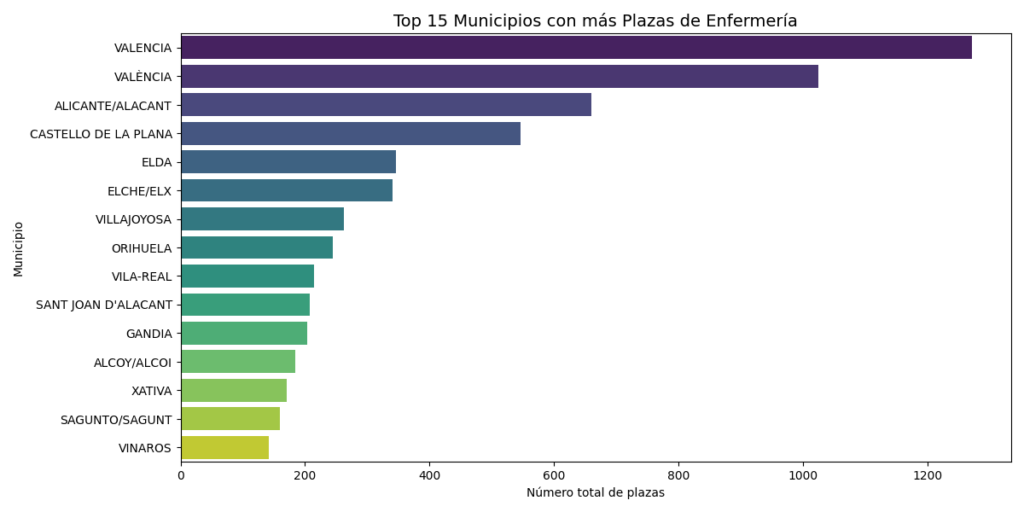
# ▶️ TOP 15 municipios con más plazas
municipio_summary = (
df.groupby("Municipio")["Num_Plazas"]
.sum()
.sort_values(ascending=False)
.head(15)
)
plt.figure(figsize=(12, 6))
sns.barplot(
x=municipio_summary.values,
y=municipio_summary.index,
palette="viridis"
)
plt.title("Top 15 Municipios con más Plazas de Enfermería", fontsize=14)
plt.xlabel("Número total de plazas")
plt.ylabel("Municipio")
plt.tight_layout()
plt.show()
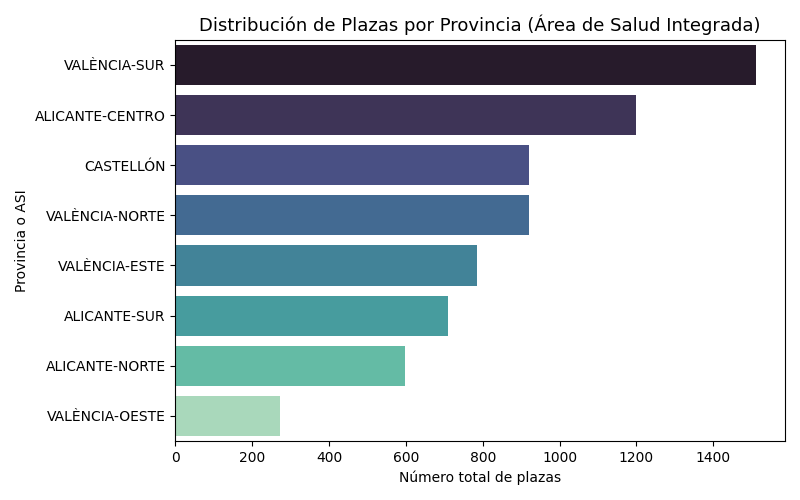
# ▶️ Distribución por Área de Salud (provincia)
if "ASI" in df.columns:
provincia_summary = (
df.groupby("ASI")["Num_Plazas"]
.sum()
.sort_values(ascending=False)
)
plt.figure(figsize=(8, 5))
sns.barplot(
x=provincia_summary.values,
y=provincia_summary.index,
palette="mako"
)
plt.title("Distribución de Plazas por Provincia (Área de Salud Integrada)", fontsize=13)
plt.xlabel("Número total de plazas")
plt.ylabel("Provincia o ASI")
plt.tight_layout()
plt.show()
🔍 ¿Qué nos dicen los gráficos?
El primer gráfico nos da una pista clara: hay municipios que concentran muchas más plazas que otros. Esto es útil no solo para detectar oportunidades, sino también para ver si los datos encajan con lo que esperamos (por ejemplo, que grandes ciudades tengan más plazas).
El segundo gráfico, por su parte, nos ofrece una visión más amplia, agrupando por áreas de salud. Nos ayuda a validar si la distribución territorial es coherente y si hay departamentos que destacan notablemente por su volumen de vacantes.
Ambos gráficos funcionan como una especie de control de calidad visual: si detectamos nombres duplicados por pequeñas variaciones (como tildes o mayúsculas), valores inesperados o municipios con cifras sospechosas, sabemos que toca revisar el proceso de limpieza o extracción.
👉 Gracias a este análisis rápido, ganamos confianza en nuestro dataset y sentamos las bases para los siguientes pasos: geolocalizar, cruzar fuentes y, finalmente, construir el visor interactivo.
2. Extracción y geoposicionamiento de centros sanitarios de la Comunitat Valenciana
Una vez tuvimos listo el listado limpio de plazas vacantes extraídas del PDF, surgió la gran pregunta: ¿dónde están exactamente estos centros?
Porque claro, tener un nombre como “CENTRO DE SALUD DE PEGO” o “CONSULTORIO AUXILIAR DE LA FONT” está muy bien, pero si no sabemos en qué punto del mapa están, es imposible visualizarlos o filtrarlos por cercanía.
Para convertir esos nombres en puntos geográficos reales, necesitábamos otro ingrediente esencial: un dataset con todos los centros sanitarios públicos de la Comunitat Valenciana, bien identificados y, sobre todo, georreferenciados (con latitud y longitud).
Por suerte, la Generalitat Valenciana publica varios conjuntos de datos abiertos sobre su red de hospitales, centros de salud, consultorios y centros de especialidades. Pero (spoiler alert) tampoco fue coser y cantar. Los datos están dispersos en varios ficheros, con formatos diferentes (CSV, GeoJSON…), columnas distintas, e incluso coordenadas en un sistema poco amigable (UTM en vez de lat/lon).
Así que tocaba otro paso clave del proyecto: unificar, transformar y geolocalizar todos esos centros para poder cruzarlos después con las plazas que habíamos extraído. ¿El objetivo? Crear un solo dataset limpio, completo y listo para poner en el mapa.
📚 2.1 Fuentes de datos abiertas
Para localizar los centros sanitarios en el mapa, necesitábamos una buena base de datos pública. Afortunadamente, la Generalitat Valenciana pone a disposición de la ciudadanía varios datasets abiertos sobre su red de centros de salud. Pero, como suele pasar, no todo es tan sencillo como parece.
Encontramos cuatro fuentes principales, repartidas entre formatos CSV y GeoJSON, que describen diferentes tipos de centros del sistema público:
- 🏥 Hospitales:
CSV disponible aquí - 🏡 Centros de Salud:
CSV disponible aquí - 🔬 Centros de Especialidades:
CSV disponible aquí - 🧭 Consultorios Auxiliares:
GeoJSON disponible aquí
Cada uno de estos datasets incluye información útil: nombre del centro, dirección, código postal, municipio, departamento de salud… y, en algunos casos, coordenadas UTM (que luego habrá que convertir a WGS-84 para poder usar en el visor).
El objetivo era claro: fusionar todas estas fuentes en un único dataset uniforme, completo y geolocalizado, con una estructura común y las coordenadas listas para usarse en un mapa interactivo. Pero para llegar hasta ahí, primero teníamos que limpiar, transformar y alinear bien todos esos datos.
🧱 2.2 Estructura de los datasets
Antes de fusionar los datos, había que entender qué teníamos entre manos. Los tres primeros conjuntos —hospitales, centros de salud y especialidades— comparten un formato muy parecido en CSV, lo que facilita mucho el trabajo. Sin embargo, el dataset de consultorios auxiliares venía en GeoJSON y con una estructura algo distinta.
.
💡 Nuestro objetivo era construir un único DataFrame que contuviera toda esta información clave:
- Código y nombre del centro sanitario
- Tipo de centro (hospital, centro de salud, especialidades, consultorio auxiliar)
- Dirección completa (calle, número, CP)
- Municipio y provincia
- Departamento de salud
- Coordenadas geográficas (latitud y longitud en WGS-84)
Estructura de los CSV (hospitales, centros de salud, especialidades)
Todos estos datasets comparten columnas con nombres similares:
| Columna | Descripción |
|---|---|
cen_cod | Código del centro sanitario |
cen_desclar | Nombre oficial o comercial del centro |
cod_ine_mun | Código INE del municipio (CPRO + CMUN) |
municipio | Nombre del municipio |
provincia | Provincia (como texto) |
cen_nombcall | Calle del centro |
cen_numcall | Número de la calle |
cen_codpos | Código postal |
codigo_departamento | Código del departamento de salud |
nombre_departamento | Nombre del departamento de salud |
x_coord / y_coord | Coordenadas UTM (EPSG:25830) |
tipo | Tipo del centro (Hospital, CS, Especialidades) |
Estructura del GeoJSON (consultorios auxiliares)
Aquí cambian un poco los nombres, y hay que adaptarlos:
| Campo | Descripción |
|---|---|
CEN_COD | Código del centro sanitario |
CEN_DESCLA | Descripción (nombre completo del centro) |
CEN_PROV | Código de provincia INE (dos dígitos, ej. 12) |
CEN_LOCA | Código de municipio INE (tres dígitos, ej. 065) |
CEN_NOMBCA | Nombre de la calle |
CEN_NUMCAL | Número de la calle |
CEN_CODPOS | Código postal |
TCE_CODI | Código de tipo de centro |
ARS_CODI | Código del departamento de salud |
ZOS_CODI | Código de zona de salud |
X_COORD | Coordenada X en UTM (EPSG:25830) |
Y_COORD | Coordenada Y en UTM (EPSG:25830)aaasdadfau |
2.3 🔁 Conversión necesaria
El siguiente paso fue adaptar el dataset de consultorios auxiliares al mismo formato que los otros tres. Esto requería varias transformaciones para que todos los centros, vinieran del CSV o del GeoJSON, pudieran unirse sin fricciones en un único DataFrame.
🔧 Estas fueron las tareas de conversión necesarias:
1. Construir el cod_ine_mun
El GeoJSON trae por separado los códigos de provincia (CEN_PROV) y municipio (CEN_LOCA), así que lo primero es unirlos:
gdf["CEN_PROV"] = gdf["CEN_PROV"].astype(str).zfill(2)
gdf["CEN_LOCA"] = gdf["CEN_LOCA"].astype(str).zfill(3)
gdf["merge_key"] = gdf["CEN_PROV"] + gdf["CEN_LOCA"]2. Asignar nombre de municipio y provincia
Usamos una tabla del INE para mapear los códigos anteriores al nombre real del municipio y la provincia. Esto nos permite añadir campos que en el GeoJSON no estaban como texto.
3. Normalizar nombres de columnas
Renombramos las columnas del GeoJSON para que coincidan con las de los CSVs y así poder concatenarlas fácilmente:
| Original (GeoJSON) | Renombrado común |
|---|---|
CEN_COD | cen_cod |
CEN_DESCLA | cen_desclar |
CEN_NOMBCA | cen_nombcall |
CEN_NUMCAL | cen_numcall |
CEN_CODPOS | cen_codpos |
ARS_CODI | codigo_departamento |
| (Mapeado) | nombre_departamento |
| (Calculado) | cod_ine_mun |
| (Mapeado) | provincia |
| (Mapeado) | municipio |
X_COORD, Y_COORD | lon, lat (tras conversión a WGS84) |
4. Añadir campos faltantes
Como el GeoJSON no incluye algunos campos (como tipo o nombre_departamento como texto), los añadimos manualmente:
df_geo["tipo"] = "consultorio auxiliar"
df_geo["nombre_departamento"] = df_geo["codigo_departamento"].map(DEPARTMENT_MAPPING)
5. Convertir coordenadas a WGS-84
Las coordenadas vienen en UTM (EPSG:25830), que debemos transformar a latitud/longitud (EPSG:4326) para usarlas en Leaflet o cualquier visor web:
from pyproj import Transformer
transformer = Transformer.from_crs("EPSG:25830", "EPSG:4326", always_xy=True)
df_geo["lon"], df_geo["lat"] = transformer.transform(df_geo["x_coord"].values, df_geo["y_coord"].values)
Con esta conversión, ya tenemos el dataset de consultorios listo para fusionarse con el resto de centros sanitarios públicos de la Comunitat Valenciana.
2.4 Proceso de transformación y normalización
Una vez adaptado el dataset de consultorios auxiliares, el objetivo era claro: construir un único fichero unificado que reuniera todos los centros sanitarios públicos de la Comunitat Valenciana con sus coordenadas geográficas, nombres normalizados y la información necesaria para enlazarlos con las plazas vacantes.
Para ello, combinamos los cuatro datasets principales:
- Consultorios auxiliares (GeoJSON, ya transformado)
- Hospitales (CSV)
- Centros de salud (CSV)
- Centros de especialidades (CSV)
Este proceso se lleva a cabo utilizando Python, con ayuda de bibliotecas como Pandas, GeoPandas y PyProj.
🧩 Paso 1. Carga del fichero de municipios del INE
Necesitábamos unificar y verificar los códigos y nombres de municipios. Para ello, usamos un Excel oficial del INE con todos los municipios de España, y filtramos solo los de la Comunitat Valenciana (códigos de provincia 03, 12 y 46):
import pandas as pd
df_municipios = pd.read_excel("data/municipiosINE.xlsx")
df_municipios.columns = df_municipios.columns.str.upper()
df_municipios["CPRO"] = df_municipios["CPRO"].astype(str).str.zfill(2)
df_municipios["CMUN"] = df_municipios["CMUN"].astype(str).str.zfill(3)
df_municipios["cod_ine_mun"] = df_municipios["CPRO"] + df_municipios["CMUN"]
🧩 Paso 2. Carga y adaptación del GeoJSON
Ya transformado en pasos anteriores, el dataset de consultorios se fusiona con el fichero del INE para obtener nombres de municipios y provincias:
import geopandas as gpd
gdf = gpd.read_file("data/consultorios_auxiliares.geojson")
gdf["CEN_PROV"] = gdf["CEN_PROV"].astype(str).str.zfill(2)
gdf["CEN_LOCA"] = gdf["CEN_LOCA"].astype(str).str.zfill(3)
gdf["merge_key"] = gdf["CEN_PROV"] + gdf["CEN_LOCA"]
df_geo = gdf.merge(df_municipios, left_on="merge_key", right_on="cod_ine_mun", how="left")
Aquí también se asigna el nombre de la provincia a partir del código de provincia (CEN_PROV) y el nombre del departamento de salud a partir de ARS_CODI, utilizando mapeos personalizados para cada provincia y cada departamento de salud, permitiendo mapear directamente los códigos numéricos expresados en el GeoJSON al texto resultado del CSV.
PROVINCE_MAPPING = {
"03": "Alacant/Alicante",
"12": "Castelló/Castellón",
"46": "València/Valencia"
}
DEPARTMENT_MAPPING = {
"01": "VINAROS",
"02": "CASTELLON",
"03": "LA PLANA",
"04": "SAGUNTO",
"05": "VALENCIA - CLINICO",
"06": "VALENCIA ARNAU LLIRIA",
"07": "VALENCIA - LA FE",
"08": "REQUENA",
"09": "VALENCIA HOSPITAL GENERAL",
"10": "VALENCIA - DR. PESET",
"11": "LA RIBERA",
"12": "GANDIA",
"13": "DENIA",
"14": "XATIVA - ONTINYENT",
"15": "ALCOI",
"16": "VILA JOIOSA",
"17": "ALICANTE - SAN JUAN",
"18": "ELDA",
"19": "ALICANTE",
"20": "ELX",
"21": "ORIHUELA",
"22": "TORREVIEJA",
"23": "MANISES",
"24": "ELX-CREVILLENT"
}
df_geo['provincia'] = df_geo['CEN_PROV'].map(PROVINCE_MAPPING)
df_geo['municipio'] = df_geo['NOMBRE']
df_geo['codigo_departamento'] = df_geo['ARS_CODI'].astype(str).str.zfill(2)
df_geo['nombre_departamento'] = df_geo['codigo_departamento'].map(DEPARTMENT_MAPPING)
🧩 Paso 3. Renombrado y estandarización de columnas
El último paso antes de fusionar todos los centros es renombrar las columnas del GeoJSON para que coincidan con los CSVs:
df_geo = df_geo.rename(columns={
"CEN_COD": "cen_cod",
"CEN_DESCLA": "cen_desclar",
"CEN_NOMBCA": "cen_nombcall",
"CEN_NUMCAL": "cen_numcall",
"CEN_CODPOS": "cen_codpos",
"X_COORD": "x_coord",
"Y_COORD": "y_coord"
})
df_geo["tipo"] = "consultorio auxiliar"
🧩 Paso 4. Conversión de coordenadas geográficas de UTM a WGS-84
Los cuatro datasets que hemos utilizado —hospitales, centros de salud, centros de especialidades y consultorios auxiliares— comparten un detalle clave: sus coordenadas están expresadas en el sistema UTM (Universal Transverse Mercator), concretamente en la zona EPSG:25830, que es el sistema oficial utilizado por muchas administraciones públicas en España.
Pero este sistema, aunque preciso para usos técnicos, no es directamente compatible con visores web como Leaflet, que utilizan coordenadas geográficas en latitud y longitud (WGS-84, EPSG:4326).
Así que tocaba traducir esas coordenadas a un formato que nuestro visor pueda entender.
🧭 ¿Cómo lo hicimos?
Gracias a la librería PyProj, esta conversión es bastante directa. Usamos un Transformer que traduce cada par de coordenadas X/Y (UTM) a sus equivalentes en lat/lon (WGS-84).
from pyproj import Transformer
# EPSG:25830 → EPSG:4326
transformer = Transformer.from_crs("EPSG:25830", "EPSG:4326", always_xy=True)
# Apply transformation
df_total["lon"], df_total["lat"] = transformer.transform(df_total["x_coord"].values, df_total["y_coord"].values)
Este paso convierte nuestras coordenadas técnicas en algo universal, interpretable por cualquier sistema de mapas moderno, desde Leaflet hasta Google Maps o QGIS.
✅ Resultado:
Cada centro sanitario ahora cuenta con sus coordenadas en latitud y longitud reales, lo que nos permitirá representarlos visualmente en el visor interactivo, calcular distancias, agrupar por proximidad… y todo lo que necesitemos en la siguiente fase del proyecto.
En el siguiente paso, realizaremos una última limpieza para eliminar columnas innecesarias y dejaremos el dataset listo para su exportación final.
🧹 Paso 5. Limpieza y eliminación de columnas innecesarias
Después de fusionar, enriquecer y convertir coordenadas, ya tenemos un dataset completo y georreferenciado. Pero aún nos queda una tarea clave antes de guardarlo definitivamente: quitar el lastre.
Muchos de los campos que arrastramos hasta ahora han cumplido ya su función (como claves de cruce, coordenadas originales UTM o columnas técnicas). Si los dejamos, no solo ocupan espacio y ralentizan el procesamiento, sino que complican el uso del dataset en el visor web y en cualquier análisis posterior.
Eliminando lo que sobra
Aquí tienes el fragmento de código que limpia el DataFrame final y se asegura de conservar solo las columnas necesarias:
# Columnas que ya no necesitamos
columns_to_drop = [
'geometry',
'merge_key',
'CPRO',
'CMUN',
'NOMBRE',
'tce_codi',
'codigo_zona',
'nombre_zona',
'CEN_PROV',
'CEN_LOCA',
'TCE_CODI',
'ARS_CODI',
'ZOS_CODI',
'CODAUTO',
'DC',
'x_coord',
'y_coord'
]
# Eliminamos solo las que existen en el DataFrame
df_total = df_total.drop(columns=[col for col in columns_to_drop if col in df_total.columns], errors='ignore')Esto asegura que el archivo resultante esté limpio, ligero y centrado en la información relevante: identificadores, nombres, ubicaciones, departamentos, tipo de centro y las coordenadas ya transformadas.
✅ Resultado:
Hemos reducido el dataset a lo esencial, dejándolo preparado para su exportación final como CSV, con más de 900 centros públicos bien organizados, limpios y listos para fusionarse con las vacantes.
Y ahora sí… ¡vamos con el paso 6! 💾
💾 Paso 6: Exportación del dataset georreferenciado final
Después de toda la limpieza, normalización, enriquecimiento y conversión de coordenadas, ya tenemos un dataset robusto, coherente y listo para usar. Es el momento de guardarlo en un formato reutilizable que sirva tanto para análisis como para alimentar el visor web de plazas vacantes.
💾 Guardando el resultado en CSV
El archivo final se exporta en formato .csv, ya con las columnas imprescindibles para representar cada centro sanitario sobre un mapa, filtrar por departamento o tipo, y vincularlo con las plazas extraídas desde el PDF:
# Save the final DataFrame as CSV
output_path = "data/centres.csv"
df_total.to_csv(output_path, index=False)
print(f"✅ Dataset exported to: {output_path}")📦 ¿Qué incluye este centres.csv?
- Código del centro
- Nombre oficial
- Tipo (hospital, centro de salud, consultorio, especialidades…)
- Dirección completa (municipio, calle, número, CP)
- Departamento de salud
- Coordenadas geográficas en formato WGS-84 (
lat,lon)
En total, el archivo reúne más de 900 centros públicos geolocalizados de la Comunitat Valenciana, listos para su uso en el visor de plazas y en cualquier tipo de análisis visual o espacial.
import pandas as pd
import geopandas as gpd
from pyproj import Transformer
# 📥 1. Cargar municipios del INE
df_muni = pd.read_excel("data/municipiosINE.xlsx")
df_muni.columns = df_muni.columns.str.upper()
df_muni["CPRO"] = df_muni["CPRO"].astype(str).str.zfill(2)
df_muni["CMUN"] = df_muni["CMUN"].astype(str).str.zfill(3)
df_muni["cod_ine_mun"] = df_muni["CPRO"] + df_muni["CMUN"]
# 📥 2. Cargar GeoJSON de consultorios auxiliares
gdf_geo = gpd.read_file("data/consultorios_auxiliares.geojson")
gdf_geo["CEN_PROV"] = gdf_geo["CEN_PROV"].astype(str).str.zfill(2)
gdf_geo["CEN_LOCA"] = gdf_geo["CEN_LOCA"].astype(str).str.zfill(3)
gdf_geo["merge_key"] = gdf_geo["CEN_PROV"] + gdf_geo["CEN_LOCA"]
# 🔁 Fusionar con INE para obtener nombre municipio y provincia
df_geo = gdf_geo.merge(df_muni, left_on="merge_key", right_on="cod_ine_mun", how="left")
# 🔗 Mapeo de provincias y departamentos
province_mapping = {
"03": "Alacant/Alicante",
"12": "Castelló/Castellón",
"46": "València/Valencia"
}
department_mapping = {
"01": "VINAROS",
"02": "CASTELLON",
"03": "LA PLANA",
"04": "SAGUNTO",
"05": "VALENCIA - CLINICO",
"06": "VALENCIA ARNAU LLIRIA",
"07": "VALENCIA - LA FE",
"08": "REQUENA",
"09": "VALENCIA HOSPITAL GENERAL",
"10": "VALENCIA - DR. PESET",
"11": "LA RIBERA",
"12": "GANDIA",
"13": "DENIA",
"14": "XATIVA - ONTINYENT",
"15": "ALCOI",
"16": "VILA JOIOSA",
"17": "ALICANTE - SAN JUAN",
"18": "ELDA",
"19": "ALICANTE",
"20": "ELX",
"21": "ORIHUELA",
"22": "TORREVIEJA",
"23": "MANISES",
"24": "ELX-CREVILLENT"
}
# ✏️ Normalización de campos
df_geo["provincia"] = df_geo["CEN_PROV"].map(province_mapping)
df_geo["municipio"] = df_geo["NOMBRE"]
df_geo["codigo_departamento"] = df_geo["ARS_CODI"].astype(str).str.zfill(2)
df_geo["nombre_departamento"] = df_geo["codigo_departamento"].map(department_mapping)
df_geo = df_geo.rename(columns={
"CEN_COD": "cen_cod",
"CEN_DESCLA": "cen_desclar",
"CEN_NOMBCA": "cen_nombcall",
"CEN_NUMCAL": "cen_numcall",
"CEN_CODPOS": "cen_codpos",
"X_COORD": "x_coord",
"Y_COORD": "y_coord"
})
df_geo["tipo"] = "consultorio auxiliar"
# 📥 3. Cargar CSV de hospitales, centros de salud y especialidades
csv_files = [
"data/hospitales.csv",
"data/centros_salud.csv",
"data/centros_especialidades.csv"
]
selected_columns = [
"cen_cod", "cen_desclar", "cod_ine_mun", "municipio", "provincia",
"cen_nombcall", "cen_numcall", "cen_codpos",
"codigo_departamento", "nombre_departamento",
"x_coord", "y_coord", "tipo"
]
df_csv = pd.concat([
pd.read_csv(path, usecols=lambda x: x in selected_columns)
for path in csv_files
])
# 🧬 4. Unir todo en un único DataFrame
df_total = pd.concat([df_csv, df_geo], ignore_index=True)
# 🌍 5. Convertir coordenadas UTM a WGS-84
transformer = Transformer.from_crs("EPSG:25830", "EPSG:4326", always_xy=True)
df_total["lon"], df_total["lat"] = transformer.transform(df_total["x_coord"].values, df_total["y_coord"].values)
# 🧹 6. Eliminar columnas no necesarias
columns_to_drop = [
'geometry', 'merge_key', 'CPRO', 'CMUN', 'NOMBRE', 'tce_codi',
'codigo_zona', 'nombre_zona', 'CEN_PROV', 'CEN_LOCA', 'TCE_CODI',
'ARS_CODI', 'ZOS_CODI', 'CODAUTO', 'DC', 'x_coord', 'y_coord'
]
df_total = df_total.drop(columns=[col for col in columns_to_drop if col in df_total.columns], errors='ignore')
# 💾 7. Guardar resultado final
output_path = "data/centres.csv"
df_total.to_csv(output_path, index=False)
print(f"✅ centres.csv creado con {len(df_total)} registros.")Este script, al ejecutarlo, te dejará listo el archivo centres.csv con más de 900 centros sanitarios públicos de la Comunitat Valenciana, todos perfectamente geolocalizados y estructurados.
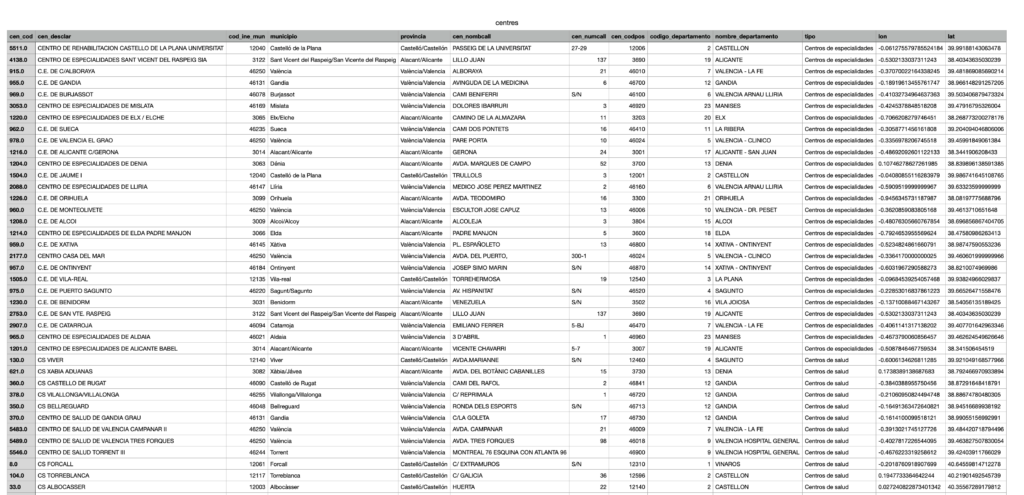
Aquí una muestra de los datos que nos ha generado el script:
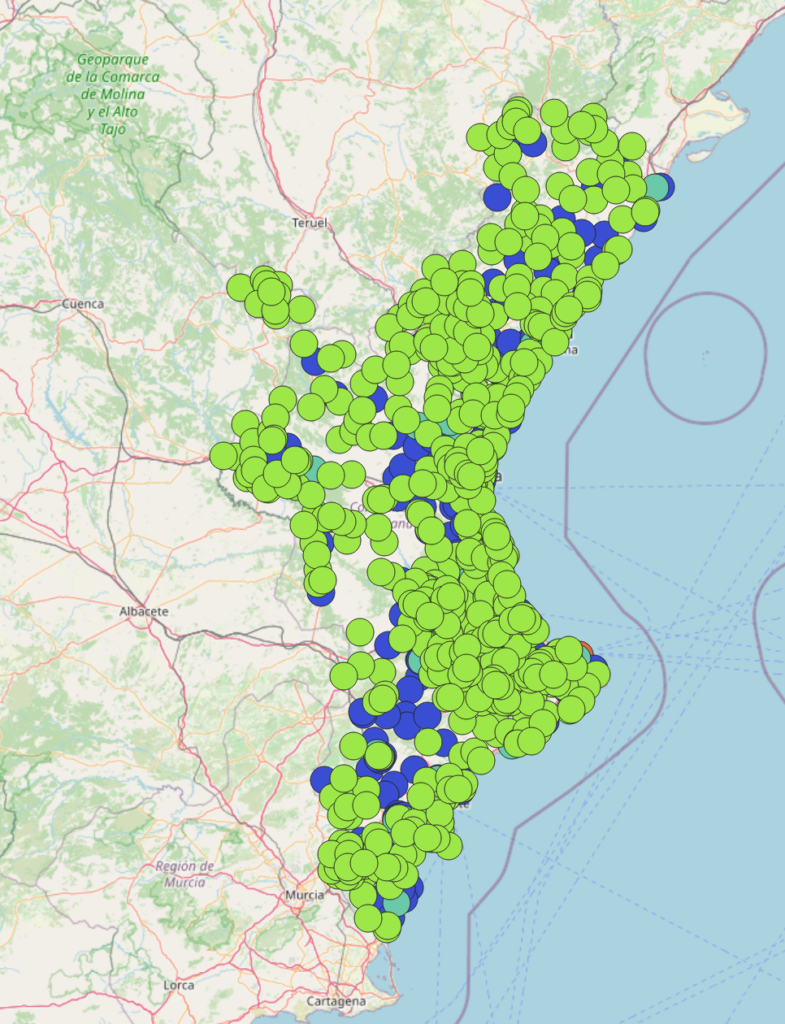
Que si los cargamos en nuestro programa GIS favorito, por ejemplo QGIS, veremos que ha hecho el trabajo correctamente y nos ha ubicado los centros sanitarios en su lugar geográfico correspondiente.
🔗 3. Unión de plazas vacantes con centros sanitarios geolocalizados
Tras haber completado la extracción de datos desde el PDF (Paso 1) y haber generado un dataset limpio y georreferenciado de los centros sanitarios públicos de la Comunitat Valenciana (Paso 2), llega el momento de unir ambas piezas en una única estructura enriquecida.
3.1 ¿Por qué es tan importante esta unión?
Porque cada plaza vacante publicada en el PDF —aunque indica un centro y un municipio— no está geolocalizada ni contiene datos homogéneos.
En cambio, nuestro dataset centres.csv sí ofrece:
- Coordenadas lat/lon del centro.
- Provincia y municipio normalizados.
- Departamento de salud asociado.
- Tipo de centro: hospital, centro de salud, consultorio…
Al combinar ambas fuentes conseguimos transformar una fila estática de un PDF en una entidad rica y visualizable en el mapa.
Este salto de calidad en los datos permite:
- Representar todas las plazas en un mapa interactivo.
- Filtrar plazas por zona, municipio o tipo de centro.
- Medir distancias reales entre centros o entre una plaza y la residencia de un profesional.
- Calcular ratios por área de salud, municipio o centro.
- Ofrecer una experiencia de usuario moderna y visual, muy alejada del tedioso PDF original.
3.2 El problema original: códigos sin contexto
Uno de los mayores obstáculos para unir correctamente las vacantes con los centros sanitarios es que los PDFs oficiales no incluyen coordenadas ni identificadores normalizados que permitan hacer un cruce directo y confiable.
En la resolución publicada por la Conselleria de Sanitat, cada plaza vacante aparece con:
- 🏷 Un código de centro de trabajo (por ejemplo,
017038) - 🏥 Un nombre de centro (por ejemplo,
CENTRO DE SALUD TORRENT)
Pero eso es todo. No hay dirección, ni coordenadas, ni referencias normalizadas.
Y para complicarlo más, ese código puede venir como "017038", 17038 o incluso 17038.0, dependiendo de cómo se haya exportado o leído el dato.
Mientras tanto, en el dataset de centros que hemos generado, esos códigos también aparecen… pero pueden estar como enteros, strings o tener formatos distintos. Y si no coinciden exactamente, el merge() de Pandas no los empareja, aunque representen el mismo centro.
🎯 La solución: normalizar antes de unir
Para evitar estos errores silenciosos, el proceso que hemos aplicado es:
- Convertir ambos códigos a enteros, eliminando ceros iniciales o decimales residuales.
- Asegurarse de que los campos de unión (
Codigo_CTycen_cod) estén en el mismo tipo de dato (Int64). - Aplicar un
merge()conindicator=Truepara saber exactamente qué filas se han emparejado.
Así, cuando el código 17038 aparece en ambos lados, Pandas lo reconoce como una coincidencia real, y nos devuelve una fila completa y unificada, lista para ser visualizada en el visor.
🔗 3.3 Unión de vacantes y centros sanitarios mediante merge()
Una vez normalizados los identificadores de centro en ambos datasets —Codigo_CT en el de vacantes y cen_cod en el de centros— llega uno de los pasos más importantes: fusionar ambos mundos para asociar cada plaza con su ubicación real.
Esta unión se realiza con merge() de Pandas, utilizando una unión izquierda (how="left"), lo que garantiza que:
- ✅ Se conservan todas las plazas vacantes.
- ✅ Se añaden los datos del centro sanitario cuando se encuentra coincidencia por código.
- ⚠️ Podemos detectar fácilmente qué plazas no han podido emparejarse gracias al parámetro
indicator=True.
Durante este proceso pueden darse tres situaciones:
📌 Centros sin vacantes (_merge == 'right_only', si se hiciera un right join, no aplicable aquí).
🔄 Coincidencias exactas (_merge == 'both'): plazas correctamente emparejadas con su centro sanitario geolocalizado.
⚠️ Plazas sin correspondencia (_merge == 'left_only'): suelen deberse a errores tipográficos, centros nuevos aún no registrados en los datasets oficiales o simplemente nombres mal formateados.
Normalización del identificador de centro: de cadena a entero
Antes de poder unir los datos de vacantes con los centros sanitarios, hay que asegurarse de que ambos datasets están “hablando el mismo idioma” cuando se trata del identificador del centro.
En el PDF original, el campo aparece como Cód C.T., que extraemos como Codigo_CT. En el dataset de centros, el campo equivalente es cen_cod. Aunque representan lo mismo, pueden diferir en forma:
- En uno puede ser una cadena de texto (
"017038"), en otro un entero (17038). - Algunos códigos tienen ceros a la izquierda.
- Incluso puede haber espacios en blanco, puntos decimales o formatos incoherentes si vienen de fuentes mixtas.
👉 Si no unificamos ese campo antes de hacer el merge, muchas coincidencias válidas se perderán por diferencias de formato.
🎯 ¿Solución? Convertir ambos a Int64
Lo más seguro es convertir ambos campos a enteros, quitando ceros sobrantes y forzando un tipo de dato uniforme (Int64 de Pandas, que permite valores nulos). Esto asegura que el código "000093" y el número 93 sean tratados como lo mismo.
import pandas as pd
# Cargar datasets
vacancies_path = "data/plazas_cleaned_simple.csv"
centres_path = "data/centres.csv"
output_path = "data/plazas_con_posicion.csv"
df_vacancies = pd.read_csv(vacancies_path)
df_centres = pd.read_csv(centres_path)
# Convertir los códigos y plazas a enteros
df_vacancies["Codigo_CT"] = pd.to_numeric(df_vacancies["Codigo_CT"], errors="coerce").astype("Int64")
df_vacancies["Num_Plazas"] = pd.to_numeric(df_vacancies["Num_Plazas"], errors="coerce").astype("Int64")
df_centres["cen_cod"] = pd.to_numeric(df_centres["cen_cod"], errors="coerce").astype("Int64")
Podemos visualizar ambos DataFrames después de haber realizado la limpieza y comprobar como los tipos numéricos ya coinciden y podemos comenzar a realizar el mergeado de ambos DataFrames.
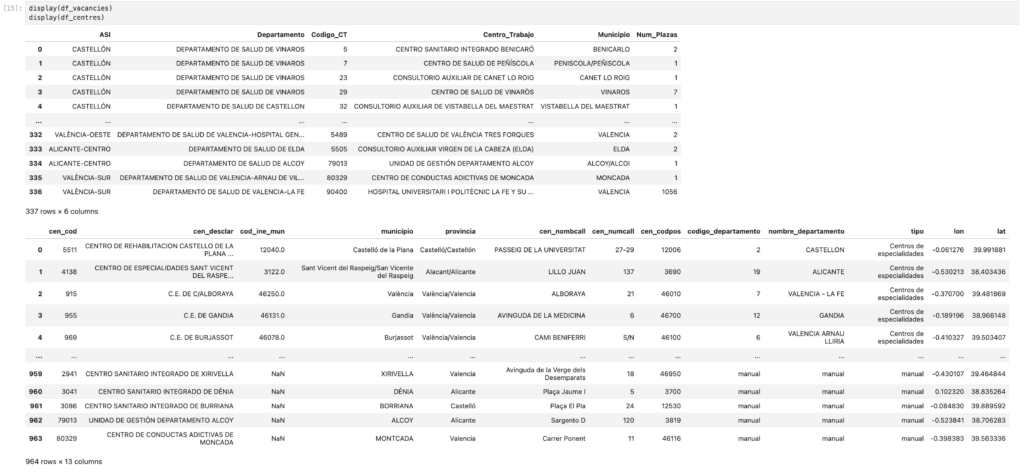
🔍 3.4 Verificación y previsualización de los datos
Antes de lanzar el merge definitivo entre las vacantes y los centros sanitarios geolocalizados, es buena idea detenerse un momento y revisar los datos que tenemos entre manos. Un paso de control que puede ahorrarnos muchos quebraderos de cabeza.
💡 ¿Por qué es importante esta verificación previa?
Porque queremos asegurarnos de que:
- Ambos DataFrames contienen las columnas clave esperadas.
- No hay valores nulos, vacíos o con formato incorrecto en los identificadores (
Codigo_CTycen_cod). - Y sobre todo: que la unión tiene sentido, que hay suficientes coincidencias posibles y no estamos a punto de ejecutar un
mergefallido.
🧪 Comprobaciones básicas con Pandas
A continuación, hacemos una pequeña previsualización y algunas estadísticas de control:
# Comprobación previa
print("🔍 Vacantes:")
print(df_vacancies[["Codigo_CT", "Centro_Trabajo", "Municipio", "Num_Plazas"]].head())
print("📍 Centros geolocalizados:")
print(df_centres[["cen_cod", "cen_desclar", "municipio", "provincia"]].head())
# Revisar valores únicos en la clave de emparejamiento
print("Código de centros (vacantes):", df_vacancies["Codigo_CT"].nunique())
print("Código de centros (centros):", df_centres["cen_cod"].nunique())
# Verificar si hay códigos duplicados
print("Códigos duplicados en vacantes:", df_vacancies["Codigo_CT"].duplicated().sum())
print("Códigos duplicados en centros:", df_centres["cen_cod"].duplicated().sum())📌 ¿Qué buscamos con esto?
- Ver ejemplos reales de los datos que se van a cruzar.
- Confirmar que hay suficientes coincidencias potenciales.
- Y detectar a tiempo si hay algo raro que nos impida seguir (por ejemplo, campos vacíos o mal formateados).
Este pequeño control de calidad nos da confianza para continuar con el paso más crítico: el cruce de datos entre las vacantes y los centros con coordenadas.

3.5 Unión de vacantes y centros sanitarios mediante merge()
Con las claves ya normalizadas y verificados ambos datasets, llegó el momento clave: unir la información de las vacantes con los centros sanitarios geolocalizados. Este paso es el que convierte un simple listado en papel en una estructura enriquecida y lista para mostrar en el visor web.
🔄 Realizando el merge
Usamos un left join para asegurarnos de no perder ninguna vacante, aunque no todas encuentren correspondencia en el dataset de centros (por ejemplo, si faltan en los datos abiertos). Además, con indicator=True podemos identificar fácilmente qué filas se emparejaron y cuáles no:
df_merged = df_vacancies.merge(
df_centres,
left_on="Codigo_CT",
right_on="cen_cod",
how="left",
indicator=True # Añade una columna _merge para saber si ha sido emparejado
)La clave indicator=True es especialmente útil, ya que añade una columna _merge con tres posibles valores:
'both': la vacante ha encontrado un centro coincidente.'left_only': la vacante no ha encontrado ningún centro geolocalizado.'right_only': centros no utilizados en el cruce (no aplicable aquí porque se usa left join).
🧾 Estadísticas tras el cruce
total_rows = len(df_merged)
matched_rows = (df_merged["_merge"] == "both").sum()
unmatched_rows = total_rows - matched_rows
print(f"✅ Total de plazas procesadas: {total_rows}")
print(f"✅ Plazas con centro geolocalizado: {matched_rows}")
print(f"⚠️ Plazas sin centro localizado: {unmatched_rows}")
✅ Total de plazas procesadas: 339
✅ Plazas con centro geolocalizado: 286
⚠️ Plazas sin centro localizado: 53
¡Nos ha encontrado 53 centros con plazas vacantes y sin estar geolocalizados!
Este resultado no es un fracaso, sino una señal de alerta. La mayoría de las plazas han sido emparejadas con éxito, pero unas cuantas requerirán atención manual. En el próximo paso veremos cómo resolverlo.
📤 Exportando las no emparejadas
Las plazas que no han conseguido emparejarse con un centro sanitario se guardan en un archivo aparte para su revisión y geolocalización manual posterior:
df_merged[df_merged["_merge"] != "both"][["Codigo_CT", "Centro_Trabajo"]].to_csv(
"data/centros_faltantes_manual.csv", index=False
)Visualizando un extracto del fichero, nos encontramos que tenemos 53 filas con dos columnas, que debemos poder geolocalizar de manera manual o de manera semiautomática.
🧩 3.6 El problema de los centros faltantes
Después de cruzar las vacantes extraídas del PDF con el dataset georreferenciado de centros sanitarios, no todas las plazas encontraron su ubicación en el mapa. En concreto, detectamos decenas de centros que no estaban presentes en los datos abiertos de la Generalitat Valenciana.
La consecuencia de esto es clara: más de 50 centros quedaban sin coordenadas geográficas, imposibilitando su representación en el visor interactivo y afectando a la experiencia del usuario.
Estos casos, lejos de ser anecdóticos, son bastante representativos de los retos reales cuando trabajamos con datos públicos. ¿Por qué sucede esto?
🧭 Posibles causas
- Centros nuevos o recién abiertos, aún no actualizados en los datasets oficiales.
- Nombres escritos de forma diferente, con tildes, abreviaturas o errores tipográficos (por ejemplo, “CS. TORRENT” vs “CENTRO DE SALUD DE TORRENT”).
- Códigos antiguos o alternativos, que ya no se corresponden con los actuales.
- Centros específicos (como unidades de salud mental, centros de conductas adictivas, o farmacias hospitalarias) que no están en los listados estándar.
- Consultorios auxiliares en municipios pequeños que no figuran en ningún dataset público descargable.
🚫 ¿Qué implicaría dejarlos fuera?
Dejar estos centros sin coordenadas supondría excluir vacantes reales del visor. Y si hay algo que queríamos evitar en este proyecto era justo eso: que los usuarios tengan que volver al PDF porque “ese centro no aparece”.
Por tanto, era necesario encontrar una alternativa para asignar ubicación geográfica a estos centros.
🧠 La solución: geolocalización manual (semi-automática)
En lugar de renunciar a esas plazas o introducir las ubicaciones manualmente una a una, opté por una estrategia intermedia: usar la API de Google Maps para localizar automáticamente estos centros por nombre, y extraer sus coordenadas y metadatos básicos (municipio, calle, código postal…).
Este paso fue fundamental para cerrar el círculo: gracias a él, logramos que el 100% de las vacantes publicadas tuvieran un punto geográfico en el mapa, permitiendo una consulta completa y visual.
En el siguiente apartado explicaremos cómo se preparó este proceso de geolocalización semiautomática con Python, geopy y la API de Google Maps.
🌍 3.7 Geocodificación automática con Google Maps y Python
Para localizar los centros que habían quedado fuera del merge original, desarrollé un script en Python que, aprovechando la API de Google Maps, transforma el nombre del centro en coordenadas geográficas (latitud y longitud) y otros datos útiles.
El flujo del proceso es el siguiente:
- Se parte del fichero
centros_faltantes_manual.csvgenerado en el paso anterior. - Para cada centro, se realiza una consulta tipo:
"Centro de Salud X, Comunitat Valenciana, España". - La API de Google devuelve las coordenadas, así como detalles adicionales:
municipio, provincia, código postal, calle, etc. - Se aplica también reverse geocoding para confirmar y enriquecer los resultados.
- Finalmente, los datos se guardan en un nuevo CSV con la misma estructura que el dataset principal.
Este paso permitió recuperar de forma automática la ubicación de más de 50 centros faltantes, sin intervención manual, mejorando la cobertura del visor y la fiabilidad de los datos.
Este proceso se dividió en dos fases:
🛠 Fase 1: Preparación del dataset
Primero, exportamos las vacantes que no habían sido emparejadas automáticamente con ningún centro sanitario georreferenciado. Este subconjunto de datos contenía únicamente el código de centro y el nombre del destino, que serán la base de nuestras búsquedas.
El objetivo aquí era tener una tabla limpia, lista para lanzar consultas automáticas a Google Maps. Para ello, preparamos el archivo centros_faltantes_manual.csv con esta estructura mínima, que luego será enriquecida con información geográfica gracias a la API de Google.
df_merged[df_merged["_merge"] != "both"][["Codigo_CT", "Centro_Trabajo"]].to_csv("data/centros_faltantes_manual.csv", index=False)📍 Fase 2: Geocodificación con Python y Google Maps
Con el CSV preparado, lanzamos un script en Python que consulta automáticamente la API de Google Maps por cada centro. Usamos la combinación del nombre del centro + «Comunitat Valenciana, España» como criterio de búsqueda, lo que nos devuelve:
- Coordenadas geográficas (latitud y longitud)
- Dirección postal completa (calle, número, municipio, código postal, provincia)
- Datos administrativos útiles para integrar en el dataset
Además, aplicamos reverse geocoding para enriquecer aún más la información de cada localización obtenida, mejorando la fiabilidad del resultado final.
🔍 Ejemplo de código aplicado:
import pandas as pd
from geopy.geocoders import GoogleV3
from geopy.extra.rate_limiter import RateLimiter
import os
import time
# Clave de la API de Google Maps
api_key = os.getenv("GOOGLE_API_KEY", "AQUI_TU_API_KEY")
if not api_key:
raise ValueError("❌ No se ha definido la variable de entorno GOOGLE_API_KEY")
# Inicializo el geocoder de Google con control de velocidad
geolocator = GoogleV3(api_key=api_key, timeout=10)
geocode = RateLimiter(geolocator.geocode, min_delay_seconds=1)
reverse = RateLimiter(geolocator.reverse, min_delay_seconds=1)
# Leo el CSV con los centros que no se han podido geolocalizar automáticamente
input_file = "data/centros_faltantes_manual.csv"
df = pd.read_csv(input_file)
# Renombrar Centro_Trabajo a cen_desclar si fuera necesario
if "Centro_Trabajo" in df.columns:
df.rename(columns={"Centro_Trabajo": "cen_desclar"}, inplace=True)
# Crear la columna cen_cod desde Codigo_CT
df["cen_cod"] = pd.to_numeric(df["Codigo_CT"], errors="coerce").astype("Int64")
# Preparo listas para ir guardando resultados
latitudes, longitudes = [], []
municipios, provincias, cod_postales = [], [], []
calles, numeros = [], []
# Bucle principal: geolocalizamos y luego sacamos datos del reverse geocoding
for _, row in df.iterrows():
query = f"{row['cen_desclar']}, Comunitat Valenciana, España"
print(f"🔍 Buscando: {query}")
try:
location = geocode(query)
if location:
lat, lon = location.latitude, location.longitude
latitudes.append(lat)
longitudes.append(lon)
print(f"✅ Coordenadas: {lat}, {lon}")
# Llamamos al reverse geocoding para sacar más detalles: calle, CP, etc.
rev = reverse((lat, lon), exactly_one=True)
components = rev.raw.get("address_components", []) if rev else []
muni, prov, cp, calle, numero = "", "", "", "", ""
for comp in components:
if "locality" in comp["types"] or "administrative_area_level_3" in comp["types"]:
muni = comp["long_name"]
elif "administrative_area_level_2" in comp["types"]:
prov = comp["long_name"]
elif "postal_code" in comp["types"]:
cp = comp["long_name"]
elif "route" in comp["types"]:
calle = comp["long_name"]
elif "street_number" in comp["types"]:
numero = comp["long_name"]
municipios.append(muni)
provincias.append(prov)
cod_postales.append(cp)
calles.append(calle)
numeros.append(numero)
else:
print("❌ No encontrado")
latitudes.append(None)
longitudes.append(None)
municipios.append("")
provincias.append("")
cod_postales.append("")
calles.append("")
numeros.append("")
except Exception as e:
print(f"⚠️ Error: {e}")
latitudes.append(None)
longitudes.append(None)
municipios.append("")
provincias.append("")
cod_postales.append("")
calles.append("")
numeros.append("")
# Esperamos un poco por si acaso para no sobrecargar la API
time.sleep(0.3)
# Añadimos todos los datos al DataFrame original
df["lat"] = latitudes
df["lon"] = longitudes
df["municipio"] = municipios
df["provincia"] = provincias
df["cen_codpos"] = cod_postales
df["cen_nombcall"] = calles
df["cen_numcall"] = numeros
df["tipo"] = "manual"
df["codigo_departamento"] = "manual"
df["nombre_departamento"] = "manual"
# Intentamos asignar el código INE del municipio usando el Excel del INE
df_muni = pd.read_excel("data/municipiosINE.xlsx")
df_muni.columns = df_muni.columns.str.upper()
df_muni["CPRO"] = df_muni["CPRO"].astype(str).str.zfill(2)
df_muni["CMUN"] = df_muni["CMUN"].astype(str).str.zfill(3)
df_muni["cod_ine_mun"] = df_muni["CPRO"] + df_muni["CMUN"]
df = df.merge(
df_muni[["cod_ine_mun", "NOMBRE"]],
left_on="municipio",
right_on="NOMBRE",
how="left"
)
df.drop(columns=["NOMBRE"], inplace=True)
# Reordenamos las columnas para que coincidan con el fichero centres.csv
cols_finales = [
"cen_cod", "cen_desclar", "cod_ine_mun", "municipio", "provincia",
"cen_nombcall", "cen_numcall", "cen_codpos",
"codigo_departamento", "nombre_departamento",
"tipo", "lon", "lat"
]
df = df[cols_finales]
# Guardamos el fichero con todos los datos necesarios para integrarlo a centres.csv
output_file = "data/centros_faltantes_geolocalizados_google.csv"
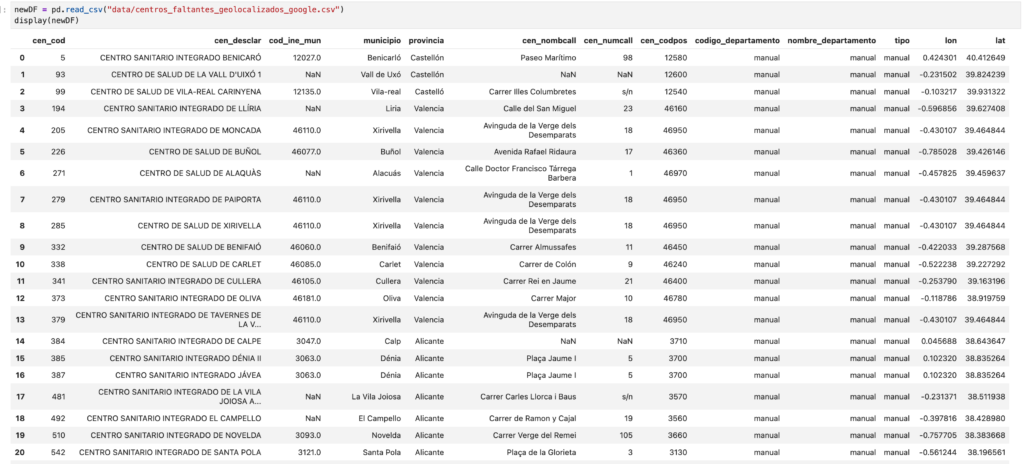
df.to_csv(output_file, index=False)Ejecutamos el script y lo dejamos unos minutos ( o segundos ) geolocalizando centros sanitarios

Posteriormente mostraremos el DataFrame con los datos actualizados
Advertencia de Geolocalización incorrecta
Este paso anterior se basa en una supuesta geolocalización automática con el Geocoder de Google Maps. Esto implica que realizará una consulta y extraerá la primera ubicación del resultado del geocoder.
Para garantizar una calidad de datos y su veracidad, en este punto se recomienda al lector que revise cuidadosamente los datos de cada uno de los centros sanitarios geolocalizados de manera semi-automática. Para este proceso bastaría con darse una vuelta por los alrededores de las ubicaciones que nos ha conseguido Google Maps y mirar a nivel de calle – si fuera posible – con StreetView, sólo así será posible determinar con mayor precisión la ubicación de estos centros sanitarios que no venían en los DataSets oficiales que nos facilita la Conselleria de Sanitat.
🧩 Fase 3 – Incorporación de los centros geolocalizados manualmente al dataset final
Una vez que hemos conseguido geolocalizar los centros sanitarios que inicialmente no estaban en los datasets abiertos —gracias a la API de Google Maps—, el siguiente paso es unificarlos con el resto del catálogo oficial de centros.
El objetivo aquí es claro: que no falte ningún centro con vacantes en nuestro visor. Da igual si estaba en los datos abiertos originales o si lo tuvimos que localizar nosotros mismos. Lo importante es que aparezca en el mapa y que cualquier enfermero pueda consultarlo.
🧱 ¿Qué contiene el nuevo fichero?
El archivo centros_faltantes_geolocalizados_google.csv incluye ahora, para cada centro que antes estaba “perdido”:
- Código y nombre del centro
- Dirección postal (calle, número, CP)
- Municipio y provincia
- Coordenadas GPS (latitud, longitud)
- Tipo de centro (en este caso:
manual) - Departamento de salud (temporalmente como
manualtambién)
Con todo esto ya listo, solo queda normalizar sus columnas para que coincidan con las del dataset principal (centres.csv) y hacer el concat() final que los una.
🧬 Unión de los dos datasets
Ya tenemos dos fuentes complementarias de información:
🔹 Por un lado, el dataset original con más de 900 centros sanitarios públicos geolocalizados.
🔹 Por otro, los centros que no aparecían en los datos oficiales, pero que hemos logrado localizar manualmente usando la API de Google Maps.
Ha llegado el momento de unificarlos en un único archivo para asegurarnos de que todas las plazas vacantes, sin excepción, tienen su centro correspondiente en el mapa.
Este paso consiste en renombrar, alinear columnas y concatenar ambos DataFrames para generar el nuevo centres.csv, listo para cruzarlo con las vacantes. ¡Vamos allá!
import pandas as pd
# --- Rutas de entrada y salida ---
path_centres = "data/centres.csv"
path_manual = "data/centros_faltantes_geolocalizados_google.csv"
# --- Cargar datasets ---
df_centres = pd.read_csv(path_centres)
df_manual = pd.read_csv(path_manual)
# --- Renombrar columnas del dataset manual si es necesario ---
rename_map = {
"Codigo_CT": "cen_cod",
"Centro_Trabajo": "cen_desclar",
"codigo_postal": "cen_codpos",
"nomb_calle": "cen_nombcall",
"num_calle": "cen_numcall"
}
df_manual.rename(columns=rename_map, inplace=True)
# --- Asegurar que 'cen_cod' es string con ceros a la izquierda ---
df_manual["cen_cod"] = df_manual["cen_cod"].astype(str).str.zfill(6)
# --- Añadir columnas necesarias si faltan ---
df_manual["tipo"] = df_manual.get("tipo", "manual")
df_manual["codigo_departamento"] = df_manual.get("codigo_departamento", "00")
df_manual["nombre_departamento"] = df_manual.get("nombre_departamento", "Desconocido")
# --- Columnas requeridas por el dataset final ---
required_columns = [
"cen_cod", "cen_desclar", "cod_ine_mun", "municipio", "provincia",
"cen_nombcall", "cen_numcall", "cen_codpos",
"codigo_departamento", "nombre_departamento",
"tipo", "lon", "lat"
]
# --- Añadir columnas faltantes con valores por defecto ---
for col in required_columns:
if col not in df_manual.columns:
df_manual[col] = ""
# --- Reordenar columnas para que coincidan con centres.csv ---
df_manual = df_manual[required_columns]
# --- Combinar datasets ---
df_combined = pd.concat([df_centres, df_manual], ignore_index=True)
# --- Guardar resultado final ---
df_combined.to_csv(path_centres, index=False)
print(f"✅ Dataset combinado actualizado y exportado a {path_centres}")
print(f"🔢 Total de centros: {len(df_combined)}")
✅ Dataset combinado actualizado y exportado a data/centres.csv
🔢 Total de centros: 966
✅ Resultado final
Con esto, nuestro fichero centres.csv contiene ahora todos los centros sanitarios públicos de la Comunitat Valenciana con vacantes en la OPE, independientemente de si venían de fuentes oficiales o si los tuvimos que geolocalizar nosotros.
Es el dataset más completo posible, y la base perfecta para enlazar todas las plazas vacantes extraídas del PDF con su ubicación real en el mapa 🗺️
Este paso era clave para asegurar que ninguna plaza se queda fuera por culpa de una falta de datos abiertos o una nomenclatura inconsistente.
🔁 3.5 Volviéndolo a juntar todo
Con todos los centros sanitarios ya geolocalizados —incluyendo aquellos que no aparecían en los datasets oficiales y que hemos localizado manualmente gracias a la API de Google Maps—, ha llegado el momento de realizar una nueva fusión con el listado de vacantes.
Este segundo merge es fundamental para garantizar que cada plaza vacante tenga asignada su localización geográfica exacta, además de los campos administrativos como municipio, tipo de centro o departamento de salud. Es la pieza clave para poder mostrar cada plaza en un mapa, filtrarla por criterios personalizados y facilitar la toma de decisiones de los profesionales.
Usamos el mismo enfoque que en pasos anteriores, asegurándonos de que los campos Codigo_CT y cen_cod estén normalizados y listos para cruzarse. Esta vez, sin embargo, esperamos que no haya plazas sin centro: el trabajo previo de geolocalización manual debería haber resuelto todos los casos pendientes.
🧪 ¿Qué buscamos validar con esta fusión final?
- Que todas las vacantes encuentren su centro en el nuevo
centres.csv. - Que las coordenadas (lat/lon) estén presentes y correctamente asociadas.
- Que no se haya perdido información clave en el proceso.
A continuación te presento el código necesario para volver a juntarlos todo y comprobar si hay – de nuevo – algún centro sanitario sin geolocalizar.
# Realizar el merge entre vacantes y centros
df_merged = df_vacancies.merge(
df_centres,
left_on="Codigo_CT",
right_on="cen_cod",
how="left",
indicator=True
)
# Estadísticas del merge
total = len(df_merged)
matched = (df_merged["_merge"] == "both").sum()
unmatched = total - matched
print(f"🔎 Total de plazas procesadas: {total}")
print(f"✅ Plazas con centro geolocalizado: {matched}")
print(f"⚠️ Plazas sin centro localizado: {unmatched}")
# Exportar los no localizados para revisar
df_unmatched = df_merged[df_merged["_merge"] != "both"][["Codigo_CT", "Centro_Trabajo"]].drop_duplicates()
df_unmatched.to_csv("data/centros_faltantes_manual.csv", index=False)
print("📤 Exportado listado de centros no localizados a 'data/centros_faltantes_manual.csv'")
# Guardar resultado final del merge
df_merged.to_csv(output_path, index=False)
Esta es la salida después de nuestra ejecución
🔎 Total de plazas procesadas: 341
✅ Plazas con centro geolocalizado: 341
⚠️ Plazas sin centro localizado: 0
📤 Exportado listado de centros no localizados a 'data/centros_faltantes_manual.csv'
¡Perfecto! 🙌 Eso significa que la integración ha sido todo un éxito.
Las 341 plazas vacantes han encontrado su correspondiente centro sanitario geolocalizado, lo cual confirma que el trabajo previo de normalización, enriquecimiento y geocodificación ha funcionado como esperábamos.
Este resultado marca un hito clave del proyecto, ya que ahora contamos con un dataset completo, coherente y preparado para ser representado en el visor interactivo. Cada plaza tiene asignada su localización exacta (latitud y longitud), lo que permitirá mostrarla en el mapa, filtrarla por criterios relevantes y generar estadísticas con total fiabilidad.
🗺️ 3.6 Visualización interactiva: creación del mapa con Folium
Con nuestro dataset final ya consolidado —todas las vacantes enlazadas a centros sanitarios con coordenadas y campos normalizados—, es hora de dar el salto visual.
Para esta fase, utilicé Folium, una librería de Python que permite generar mapas interactivos basados en Leaflet directamente desde un Jupyter Notebook o script. Es ideal para prototipar rápidamente y obtener una representación visual clara sin necesidad de desarrollar una app frontend desde cero.
🎯 Objetivo del visor:
- Permitir al usuario explorar, agrupar y localizar fácilmente los destinos disponibles.
- Mostrar cada plaza vacante como un marcador en el mapa.
- Usar distintos colores según el tipo de centro (hospital, centro de salud, consultorio, etc.).
- Añadir popups con información útil: nombre del centro, municipio, número de plazas, departamento.
- Incluir capas base como ortofoto del PNOA y cartografía del IGN.
import pandas as pd
import folium
from folium.plugins import MarkerCluster, Fullscreen, LocateControl
# Cargar dataset de plazas con coordenadas
df = pd.read_csv("data/plazas_con_posicion.csv")
df = df.dropna(subset=["lat", "lon"])
# Crear mapa base
mapa = folium.Map(
location=[39.5, -0.5],
zoom_start=8,
control_scale=True,
tiles=None
)
# Capas base
folium.TileLayer("OpenStreetMap", name="OpenStreetMap").add_to(mapa)
folium.WmsTileLayer(
url="https://www.ign.es/wms-inspire/pnoa-ma?",
layers="OI.OrthoimageCoverage",
name="PNOA (Satélite)",
attr="IGN-PNOA",
transparent=True,
overlay=False,
control=True
).add_to(mapa)
folium.WmsTileLayer(
url="https://www.ign.es/wms-inspire/ign-base?",
layers="IGNBaseTodo",
name="IGN Base",
attr="IGN",
transparent=True,
overlay=False,
control=True
).add_to(mapa)
# Agrupación de marcadores
marker_cluster = MarkerCluster(name="Plazas de Enfermería").add_to(mapa)
# Función de color de icono
def get_color(tipo):
tipo = str(tipo).lower()
if "hospital" in tipo:
return "red"
elif "centro de salud" in tipo:
return "blue"
elif "consultorio" in tipo:
return "green"
elif "especialidad" in tipo:
return "purple"
return "gray"
# Añadir marcadores
for _, row in df.iterrows():
plazas = row.get("Num_Plazas", 0)
tiene_plazas = pd.notna(plazas) and int(plazas) > 0
popup_html = f"""
<div style="width: 350px; font-family: Arial;">
<h4>{row.get('cod_ct', '')} - {row.get('cen_desclar', '')}</h4>
<p><b>Municipio:</b> {row.get('municipio', '')}<br/>
<b>Departamento:</b> {row.get('nombre_departamento', '')}<br/>
<b>Plazas:</b> <span style="color: {'green' if tiene_plazas else 'red'}; font-weight: bold;">
{plazas if tiene_plazas else 'Sin plazas'}</span></p>
</div>
"""
folium.Marker(
location=[row["lat"], row["lon"]],
popup=folium.Popup(popup_html, max_width=350),
icon=folium.Icon(color=get_color(row.get("tipo", "")), icon="plus-sign")
).add_to(marker_cluster)
# Plugins extra
Fullscreen(position="topright").add_to(mapa)
LocateControl(position="topright").add_to(mapa)
# Control de capas
folium.LayerControl(position="bottomright", collapsed=False).add_to(mapa)
# Guardar mapa final
mapa.save("mapa_plazas.html")Tras correr este último script nos aparecerá en el directorio el fichero mapa_plazas.html que es el que contendrá nuestros centros de sanitarios en los que existen plazas, geolocalizados .
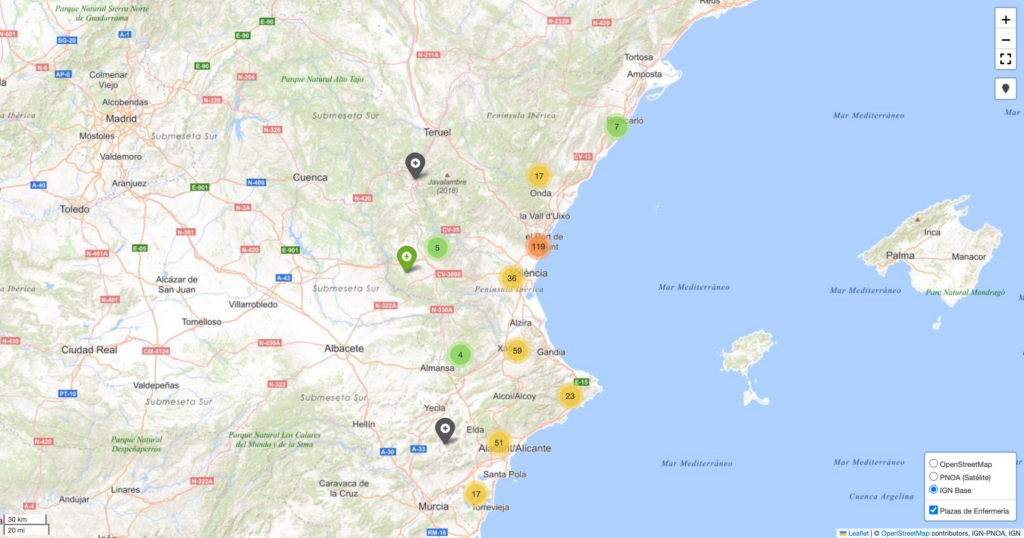
🧭 Cierre de la Parte 1: del caos al mapa
Convertir un PDF interminable y mal estructurado en un visor geográfico ha sido, literalmente, un ejercicio de ingeniería inversa. Porque lo que debería ser sencillo —acceder a un listado público y reutilizable de plazas sanitarias— se convierte en un laberinto burocrático, donde la administración sigue publicando información crucial en formatos cerrados, sin estructura, sin metadatos y sin geolocalización.
En pleno 2025, seguimos sin un dataset oficial unificado de centros sanitarios de la Comunitat Valenciana con coordenadas GPS, códigos INE o una API pública. Y sin embargo, esos datos existen. Están dispersos, incompletos, ocultos tras formularios, en PDFs o GeoJSONs mal documentados. Lo frustrante no es solo que falten, sino que nadie en la administración parece tener la voluntad de unirlos.
Por suerte, los datos abiertos y las herramientas libres (Python, Pandas, GeoPandas, Folium…) nos permiten revertir esa situación. Hemos construido una base sólida: 341 plazas correctamente geolocalizadas y listas para ser exploradas como nunca antes.
📍 En la Parte 2, daremos el siguiente gran paso: transformar estos datos en una app web usable, visual y pensada para personas reales. Con filtros, mapas interactivos, KPIs y estadísticas que sí ayudan a tomar decisiones.
Si te ha gustado esta primera parte, no te pierdas la segunda: porque no basta con abrir los datos, hay que convertirlos en algo que realmente empodere a quienes los necesitan.
Y sí, vamos a hacer exactamente eso. 😉




